
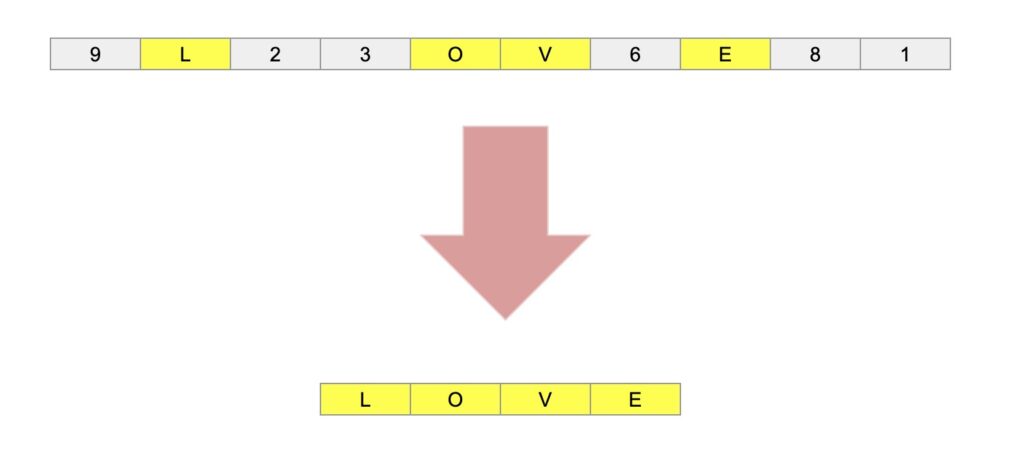
この記事ではアセンブラ言語で、文字コードの比較を使って文字列の中から大文字の英字である、「LOVE」を取り出すことを学べます。
単調な勉強ではありますが、「推し」がいる方は推しの方への思いを込めて手を動かして頂けたらと思います。
この記事では、こちらのWebのシミュレーターを使っています。
ダウンロードすることなく、素早くアセンブラの勉強が出来る、私が使った中で1番便利なシミュレーターです。
上記ような、英字と数字が混在した文字列の中から、文字コードを比較して、英字のみを取り出します。
コードを掲載する前に、各汎用レジスタがどのような動きをするのか、図解で掲載致します。
数字の文字コードは、’1’が「0031」、’2’が「0032」・・・’9’が「0039」です。
それに対して英語の大文字は、’A’が「0041」、’B’が「0042」・・・’Z’が「005A」になります。
今回抽出する文字列の、LOVEは、
‘L’…「004C」
‘O’…「004F」
‘V’…「0056」
‘E’…「0045」
になります。
元の文字列(BEFORE)の「9L23OV6E81」の中から、英文字である「L,O,V,E」を取り出します。
どのようにして取り出すのかというその仕組みを簡単に書くと、
・文字コードの比較を行い、数字や記号の場合はスキップする
・英字の場合は出力文字列(AFTER)に格納する
と言った仕組みです。
比較を使って、文字コードが数字の’9’以下の文字の場合は処理をスキップ致します。
前述の通り英文字の文字コードは、数字よりも大きいで、その文字コードの大きさで、英文字か数字かを判断しています。
文字コードについて不安な方は、こちらの外部記事が分かりやすいです。
文字列の位置が分かるような図を掲載致します。
(下の図を見ても分かりづらい場合でも、プログラムを動かしながら1つずつトレースをして行きますので、安心して下さい。)
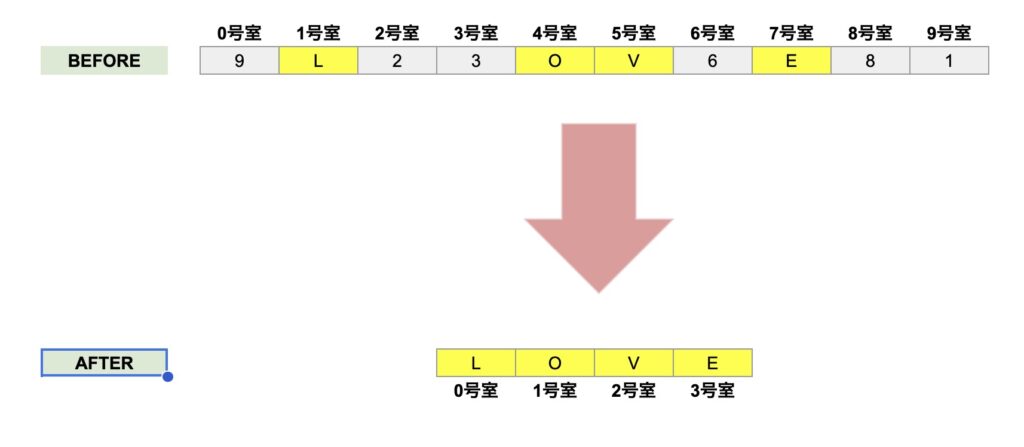
元の文字列「BEFORE」は、0号室、1号室…9号室まであります。
全部で10文字分なので、BEFOREの文字数BLENにはDCで10を入れます。
出力用の文字列「AFTER」は、0号室、1号室…3号室まであります。
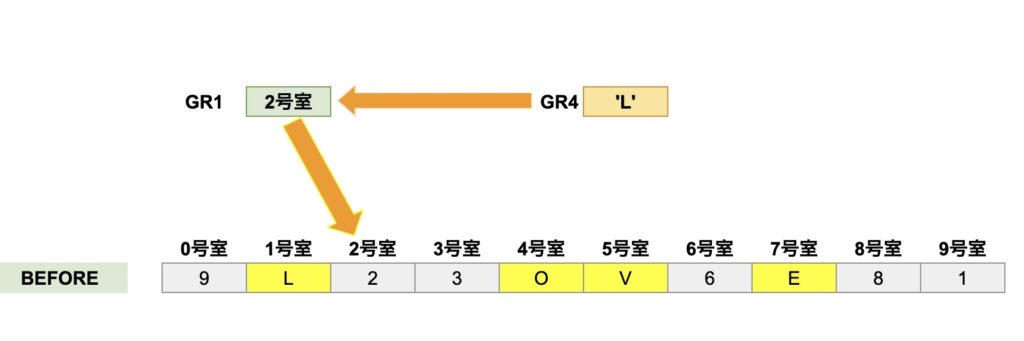
GR1は、元の文字列BEFOREの先頭アドレス「0号室」を指します。
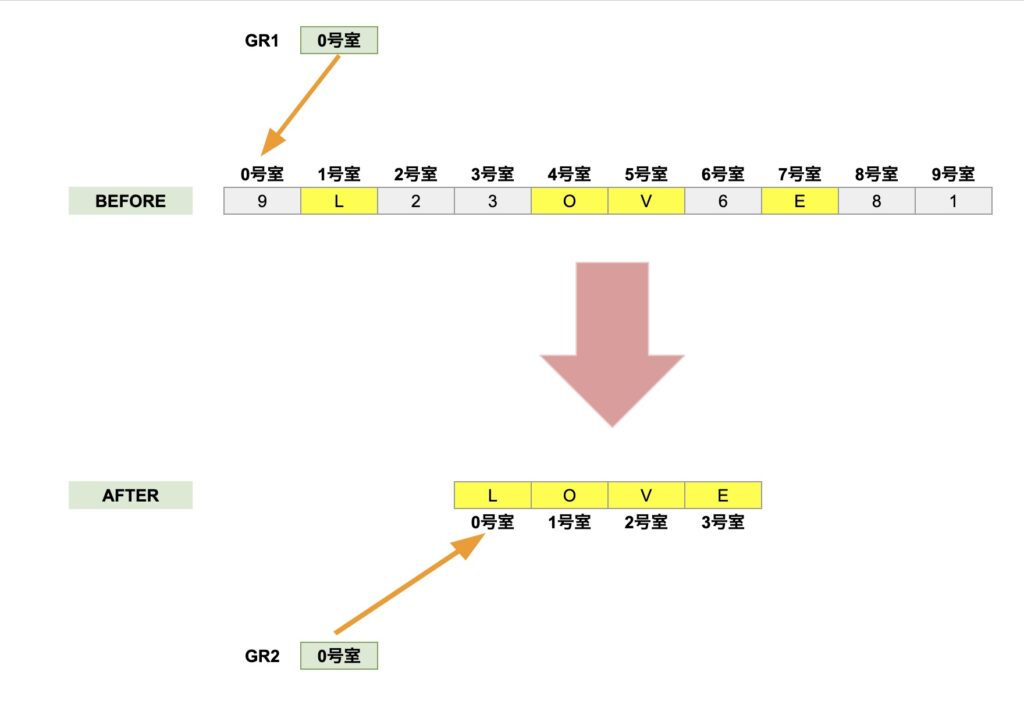
GR2は、出力用文字列AFTERの先頭アドレス「0号室」を指します。
GR4は、GR1が指す「元の文字列BEFOREの0号室の住人」の「’9’」さんを安否確認するように見つめています。


GR3は処理した文字数のカウントに使います。
元の文字列BEFOREの文字数が10文字ですので、処理した文字数をカウントするGR3が10と等しくなった時に、FINラベルに分岐してループを抜けた後に出力処理に移ります。
最初は処理した文字数のカウントのGR3の値は0でBEFOREの文字の長さ(BLEN)の10文字より小さいので、ループの処理を行います。
ループの中で、 GR4が見ている「’9’」さんが「’0’(ゼロ)」さんより小さいか
どうかの判断します。(小さい場合は、「’!’」や「スペース」などの記号です。)
小さくは無いので、このまま進めます。
「’9’」さんは「’9’」と等しいかを判断します。
当てはまったので、英文字ではないことが分かります。
つまり、出力すべき「L,O,V,E」ではないので、処理せずにSKIPへ行きます。
SKIPしたところでは、GR1を0号室から1号室に進めます。

処理した文字数を1つ増やすので、カウントに使うGR3の値が0から1になります。

JUMP命令で、LOOPに戻ります。
ループを続けるのかの判断で、先ほどの図の通り処理した文字数のカウントに使っているGR3が1で、BEFOREの文字の長さBLENの10文字よりも小さいので、ループの処理を行います。
GR1の値が先頭アドレスの0号室から、1つ移動したので、GR1が1号室を指し示します。
今度はGR4は、「’9’」さんの隣にいる「’L’」さんを、安否確認する様に見ています。

GR4が安否確認する様に見ている、 「’L’」さんが英大文字かどうか判断します。
‘L’さんの文字コードは「004C」で、’9’の「0039」よりも大きいので、出力用の文字列のAFTERに格納する処理を行います。
出力用の文字列AFTERのGR2が指し示す0号室に、「’L’」さんを入室許可します。
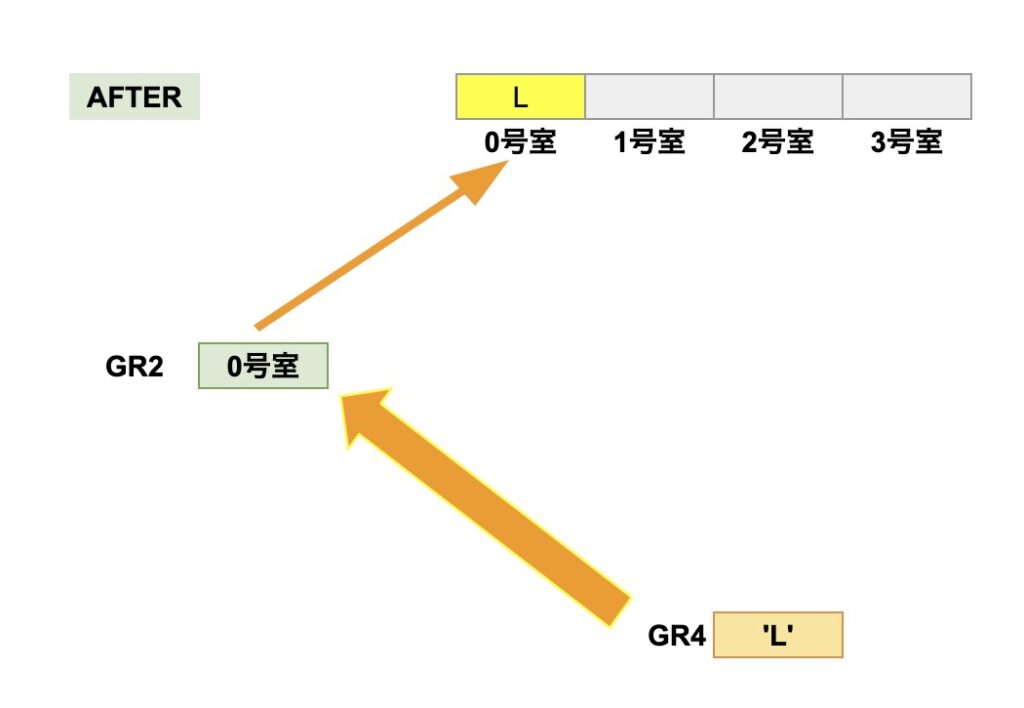
出力用の文字列AFTERを1つ進めて、GR2は1号室を指します。
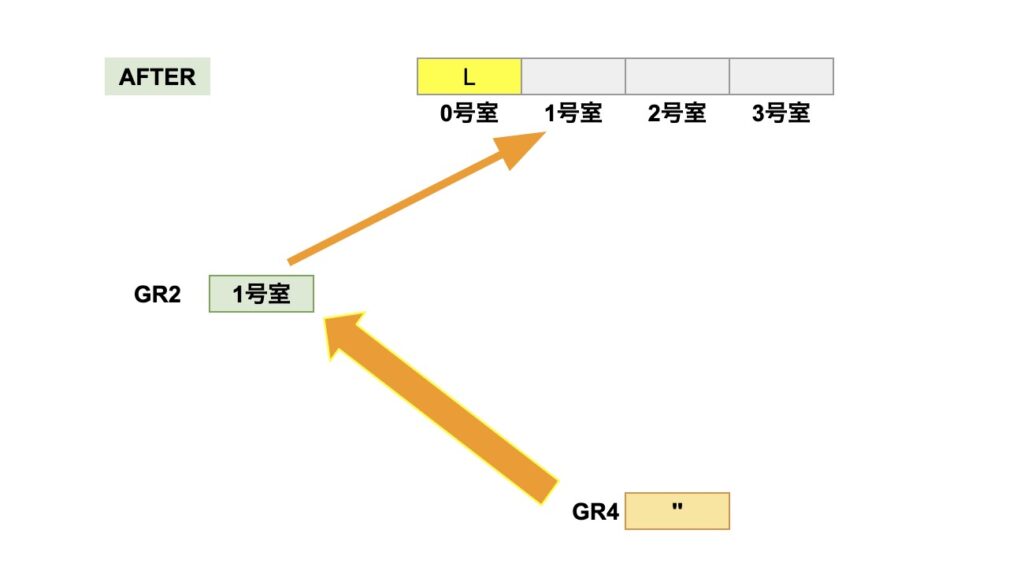
元の文字列BEFOREも1つ進めて、GR1は2号室を指します。
処理した文字を1つ増やすので、 GR3が2になります。

その後、またループに戻ります。
ということを繰り返して、「L,O,V,E」と取り出していきます。
それではソースを掲載して、実際にシミュレーターで動かして行きます。
上記の図を見て分かりにくいと思われても、1つ1つトレースをしてシミュレーターの図でレジスタの値の変化が分かるようにスクショしましたので、安心して下さい。
TEST START
RPUSH
LAD GR1,BEFORE ;GR1に元の文字列BEFOREの先頭アドレスを格納する
LAD GR2,AFTER ;GR2に出力用の文字列AFTERの先頭アドレスを格納する
LAD GR3,0 ;GR3に処理した文字数をカウントする
;<<ここからループ>>
LOOP CPL GR3,BLEN;GR3のカウント数と元の文字列の長さBLENを比較する
JZE FIN;GR3のカウントが元の文字列の長さと等しかったらFINに分岐する
LD GR4,0,GR1;GR4に元の文字列からGR1が指し示すアドレスに入っている文字を取得する
CPL GR4,='0';GR4の文字と'0'(ゼロ)を比較する
JMI SKIP;'0'より小さかったらSKIPへ分岐する
CPL GR4,='9';GR4の文字と'9'を比較する
JMI SKIP;'9'より小さかったらSKIPへ分岐する
JZE SKIP;'9'と等しかったらSKIPへ分岐する
;出力すべき英字なので出力用の配列に格納する
ST GR4,0,GR2;GR4の文字を出力用の文字列AFTERに格納する
LAD GR2,1,GR2;出力用の文字列AFTERを指し示すGR2を1つ先に進める
;数字・英字共通のSKIPラベル
SKIP LAD GR1,1,GR1;元の文字列BEFOREを1つ先に進める
LAD GR3,1,GR3;処理した文字数のカウント用のGR3をインクリメント
JUMP LOOP;ループへ戻る
;<<ループはここまで。>>
;ループを抜けた後の出力処理
FIN OUT BEFORE,BLEN;元の文字列を出力する
LAD GR1,AFTER;GR1に出力用文字列AFTERの先頭アドレスを読み込む
SUBL GR2,GR1;出力用文字列AFTERの現在のアドレスGR2から先頭アドレスのGR1を引く
ST GR2,ALEN;上で求めた文字数を出力用文字列の文字数ALENに格納する
OUT AFTER,ALEN;出力用の文字列AFTERを出力する
BEFORE DC '9L23OV6E81';元の文字列BEFORE
BLEN DC 10 ;元の文字列の文字数BLENを10文字とする
AFTER DS 20;出力用文字列AFTERの領域を20確保
ALEN DS 1;出力用の文字数AFTERの領域を1確保
RPOP
RET
ENDそれでは実行して、シミュレーターを動かして1つずつトレースをしていきます。
GR1に、元の文字列BEFOREの先頭のアドレスが入ります。
(GR1とGR2の値は、実行環境によって異なりますので、増加の状態以外は気にしないで下さい)

GR2に出力する文字列AFTERの先頭のアドレスが入ります。

GR3に文字処理のカウント数ゼロが入ります。

GR3の0と元の配列の長さBLEN(=10)を比較し、GR3の方が小さいので、サインフラグSFがマイナスになります。

GR3はBLENと等しくないので、分岐はしません。
GR4に元の文字列BEFOREの最初の文字である’9’が入ります。
‘9’の文字コードは「0039」です。
GR4の文字’9’と’0’を比較します。
小さくないので、サインフラグはSFはそのままです。

そのため、分岐はしません。
次に、GR4の文字’9’と’9’が等しいか比較します。
等しいのでゼロフラグZFが立ちます。
JMIで9より小さい、JZEで9と等しい場合はSKIPに分岐します。
アセンブラでは他の言語みたいに「<=」で以下という表記はできない為、
以下ということは、「より小さい」と「等しい」の2つの処理に分割して記述しています。
この場合、’9’「以下」なのでJZEでSKIPに分岐して、出力するLOVEではないので、出力に関する処理を飛ばしています。
SKIPでは、元の文字列BEFOREを1つ先に進めます。
処理した文字数のGR3をインクリメントします。
ループに戻ります。
ループの先頭では、処理した文字数GR3の1と文字列BEFOREの長さBLENの10を比較します。
GR3の方が小さいので、SFのフラグが立ちました。
BLENと等しくないので、このままループを続けます。
GR4に、BEFOREの文字列 ‘L’ を取得します。
‘L’ の文字コードは「004C」です。
‘L’が’0’や’9’以下かどうか比較します。
小さくないのでSKIPに分岐せずに出力用文字列AFTERへの格納処理を行います。
GR4の文字’L’をAFTERに格納します。
AFTERを1つ先へ進めます。

と繰り返して行き、文字列処理カウントのGR3が9になる所まで飛ばして、そこからトレースします。
・
・
・
シミュレーターの値はこの様になっています。
GR4にBEFOREの最後の文字 ‘1’ が入りました。
‘1’ の文字コードは「0031」です。
GR4の’1’は’0’より大きいですが’9’より小さいので、SFフラグが立ってSKIPに分岐します。

元の文字列BEFOREを1つ進めます。
処理した文字数のGR3をインクリメントします。
ループに戻ります。
処理した文字数のGR3と文字数BLENの10を比較し、等しいのでゼロフラグZFが立ちます。
JZEよりFINに分岐して文字列を出力します。
元の文字列BEFOERを出力します。

出力用の文字列AFTERの先頭アドレスをGR1に入れます。
出力用の文字列の現在のアドレスGR2から先頭のアドレスGR1を引きます。
GR2にAFTERの文字数が4文字であることが求まります。
GR2の求めた文字数をAFTERの文字数ALENに格納します。
AFTERを出力します。

お疲れ様でした。
ここで一旦、写真で休憩を挟みます。

恵比寿ガーデンプレイスのシャンデリアです。
クリスマスイルミネーションで、フランスのクリスタルメーカー、バカラのものです。
ここから、復習&アウトプットタイムです!!
下記のコードをシミュレーターにコピペして、コメントを頼りに先ほどのコードを覚えているか入力して見て下さい。
上手く動いたら、値などを好きなように変えて動かして見て下さい。
この復習は学習直後は勿論、明日など少し日を開けて行うと、更に効果的です!!
このコードですと、出力する文字列をあなたの推しの名前にしてみたら、きっと楽しいですし、理解も深まると思います!
TEST START
RPUSH
;GR1に元の文字列BEFOREの先頭アドレスを格納する
;GR2に出力用の文字列AFTERの先頭アドレスを格納する
;GR3に処理した文字数をカウントする
;<<ここからループ>>
;GR3のカウント数と元の文字列の長さBLENを比較する
;GR3のカウントが元の文字列の長さと等しかったらFINに分岐する
;GR4に元の文字列からGR1が指し示すアドレスに入っている文字を取得する
;GR4の文字と'0'(ゼロ)を比較する
;'0'より小さかったらSKIPへ分岐する
;GR4の文字と'9'を比較する
;'9'より小さかったらSKIPへ分岐する
;'9'と等しかったらSKIPへ分岐する
;出力すべき英字なので出力用の配列に格納する
;GR4の文字を出力用の文字列AFTERに格納する
;出力用の文字列AFTERを指し示すGR2を1つ先に進める
;数字・英字共通のSKIPラベル
;元の文字列BEFOREを1つ先に進める
;処理した文字数のカウント用のGR3をインクリメント
;ループへ戻る
;<<ループはここまで。>>
;ループを抜けた後の出力処理
;元の文字列を出力する
;GR1に出力用文字列AFTERの先頭アドレスを読み込む
;出力用文字列AFTERの現在のアドレスGR2から先頭アドレスのGR1を引く
;上で求めた文字数を出力用文字列の文字数ALENに格納する
;出力用の文字列AFTERを出力する
BEFORE DC '9L23OV6E81';元の文字列BEFORE
BLEN DC 10 ;元の文字列の文字数BLENを10文字とする
AFTER DS 20;出力用文字列AFTERの領域を20確保
ALEN DS 1;出力用の文字数AFTERの領域を1確保
RPOP
RET
END皆さま、大変お疲れ様でした。
この記事最後のブレイクタイムPhotoは・・・



恵比寿ガーデンプレイスのクリスマスイルミネーションです。
仕事や勉強のリフレッシュに、趣味で写真を撮っておりますので、宜しかったら フォトストック写真ACさん の投稿もご覧頂けますと、大変嬉しい限りでございます!!
こちら、無料の「ダウンロードユーザー」に登録して頂けると、無料で写真のダウンロードが可能になります。
※ 先にGoogleアカウントを作成して頂くと、登録が ラク です♪

最後までご精読、誠にありがとうございました!!
自己紹介
アセンブラ自作サンプルとFE出題範囲のアリゴリズムへ
アセンブラ過去問プログラムへ
プログラミング未経験者はアセンブラと表計算どっち!?
基本情報技術者試験トップへ
午前免除試験
午後試験のオススメ本
スコアレポート