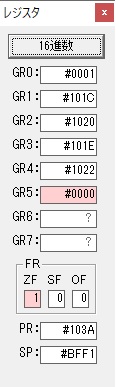
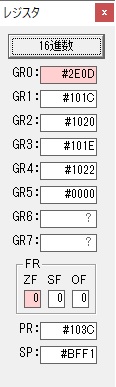
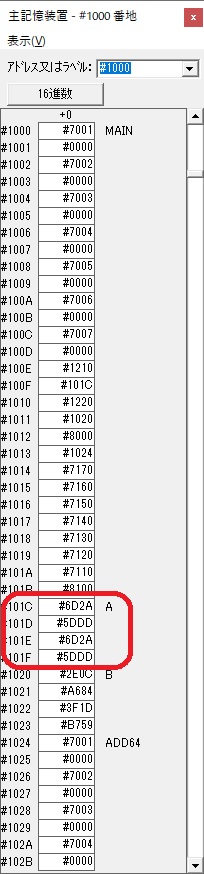
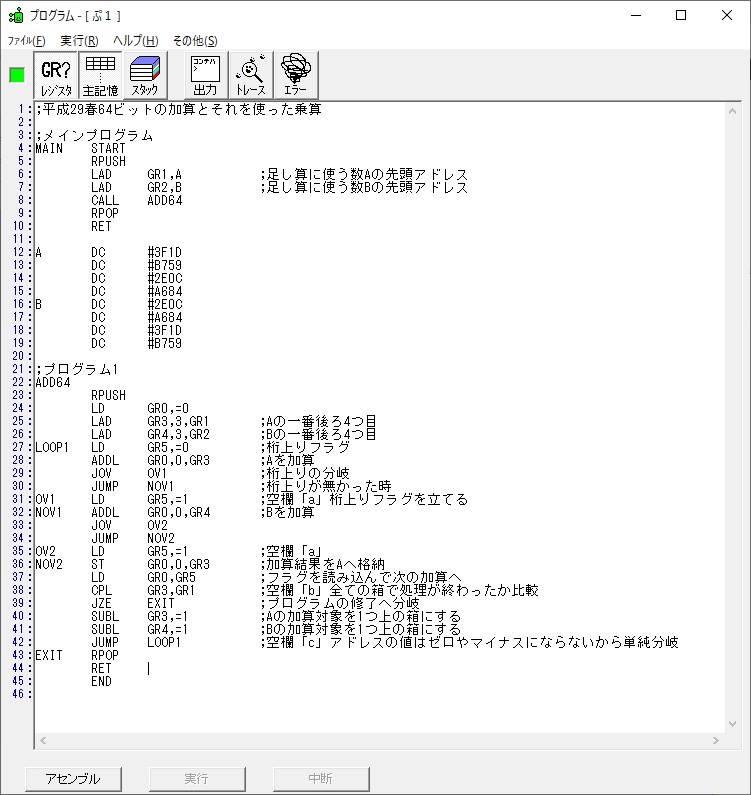
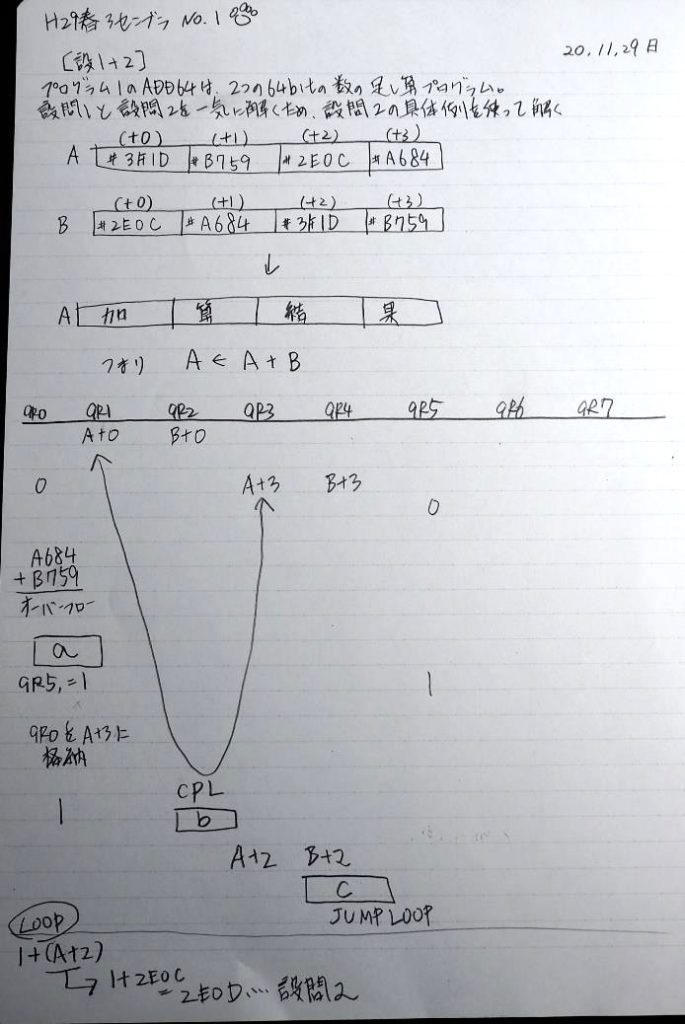
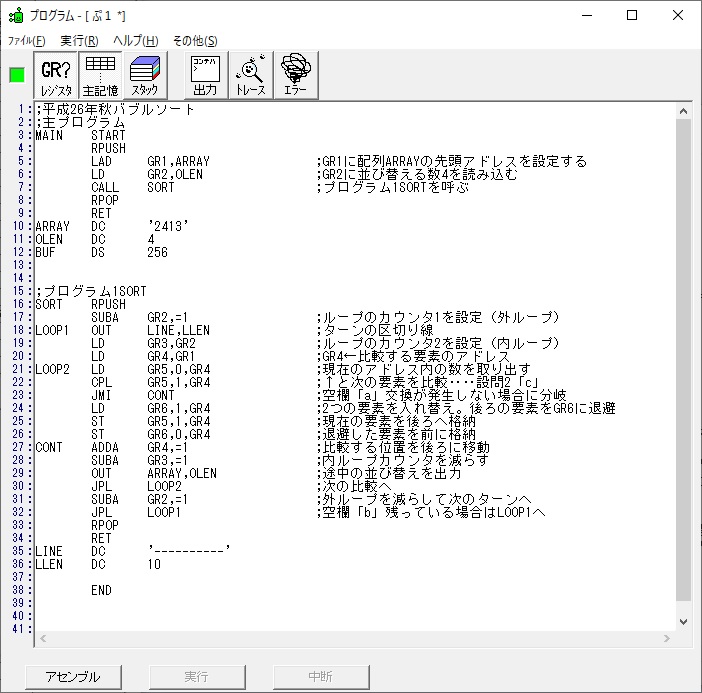
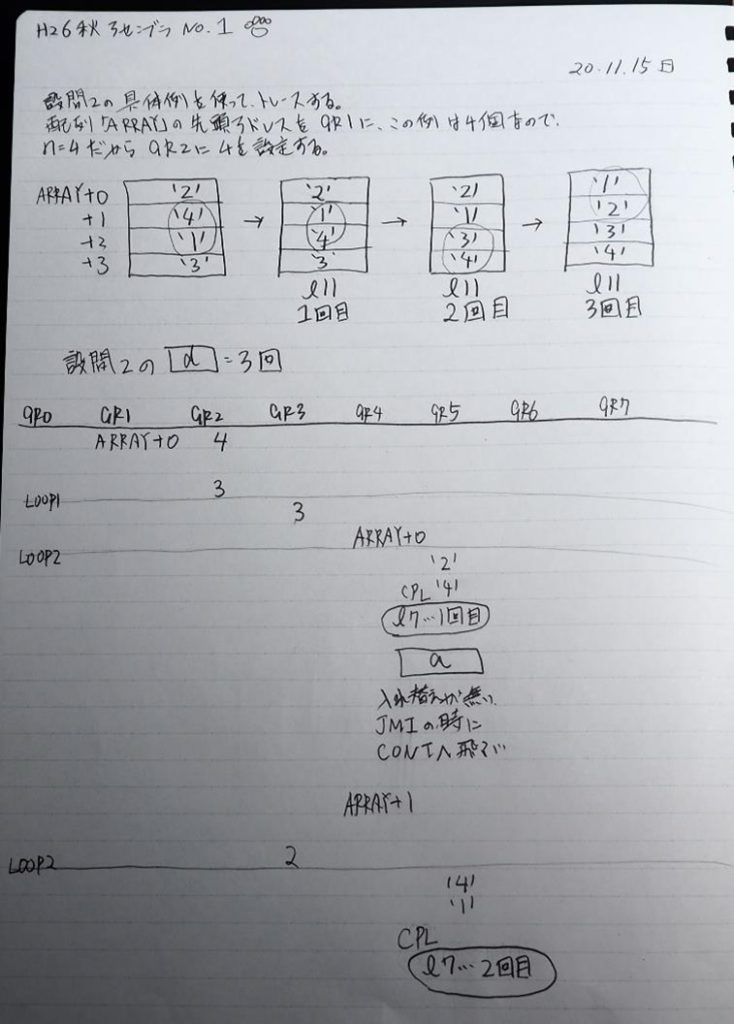
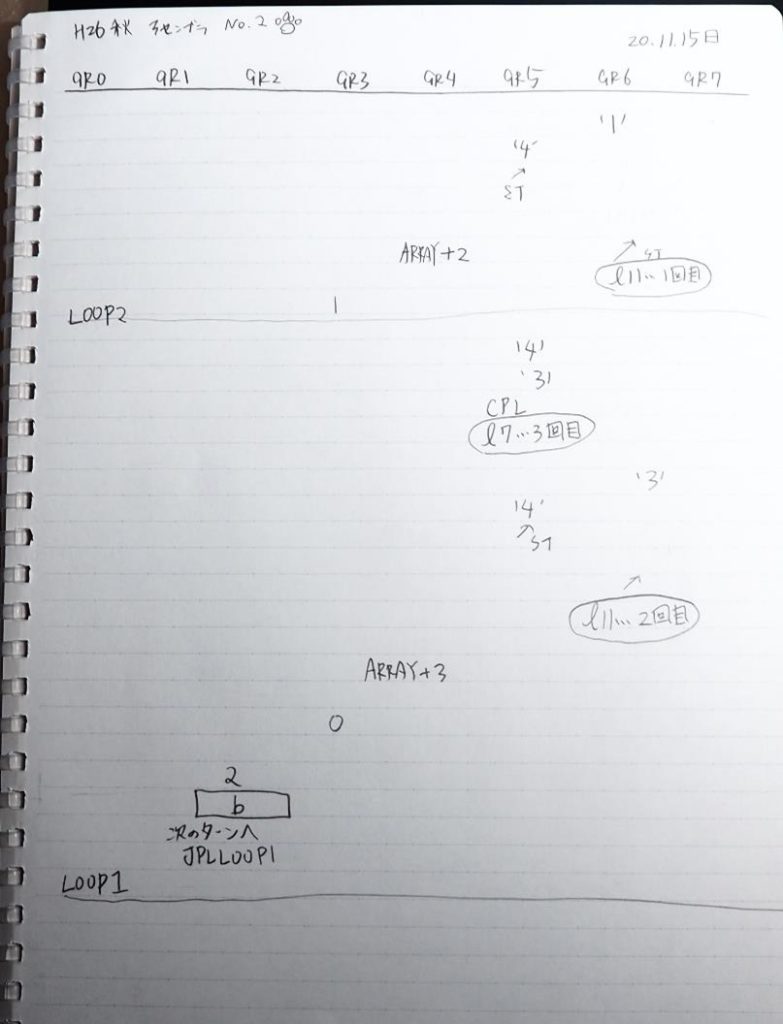
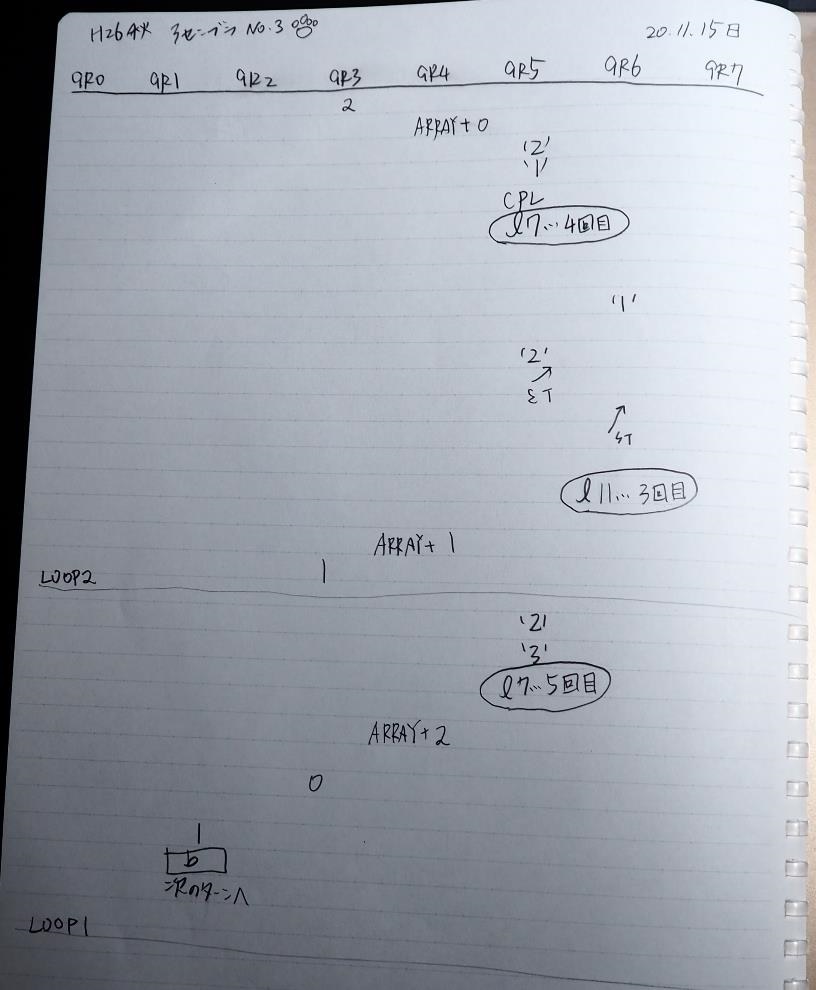
この記事では、過去問のアセンブラの問題に載っているプログラムを実際に自分の環境で作成して動かすのに使ったコードと、トレースのノートを掲載しています。
アセンブラ過去問プログラミング アセンブラ自作サンプルへ 基本情報技術者試験トップへ 令和2年度(令和3年1月合格報告)
シミュレーターと過去問を解くまでの勉強に使った参考書はこちら
この過去問を解いたのは2020年(令和2年)11月8日から9日にかけてです。
後手後手にしていた年末調整、やっと終わりましたので(褒めて褒めて!!)、安心して過去問に取り掛かれました。
さて、過去問に入ります。この過去問題も、アセンブラ色強いな、と思いました。
アセンブラ色が強いな、と思ったのは、特にプログラム1の時間換算で10倍にする処理が出て来て、10バイトは2倍×2倍×2倍の8倍に 2倍を加えた計算が出て来る所で、右シフト左シフトを使ってオーバーフローした場合の分岐が出て来る所です。
個人的にはプログラム1>プログラム3>プログラム2
では、実際に見ていきます。
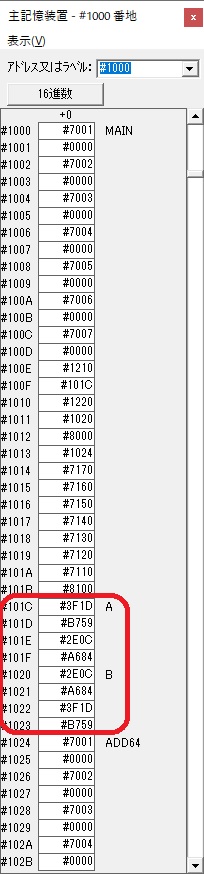
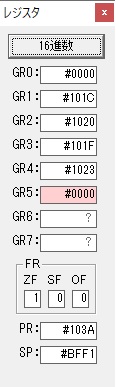
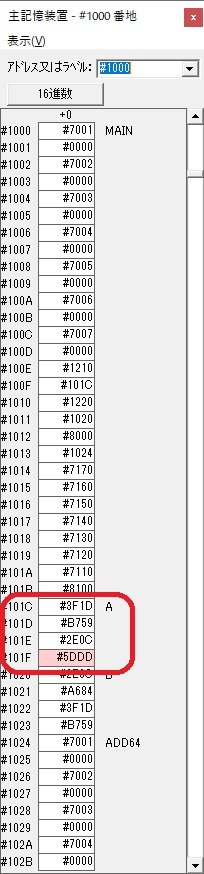
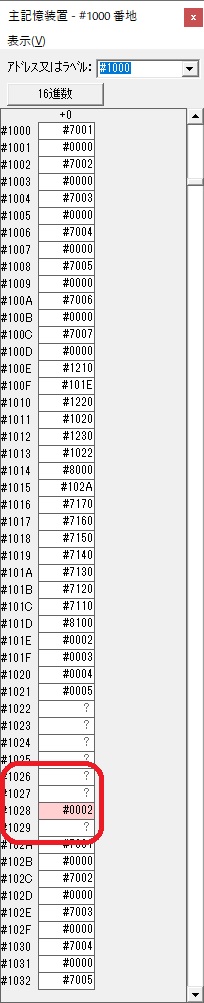
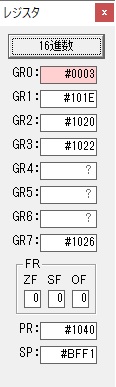
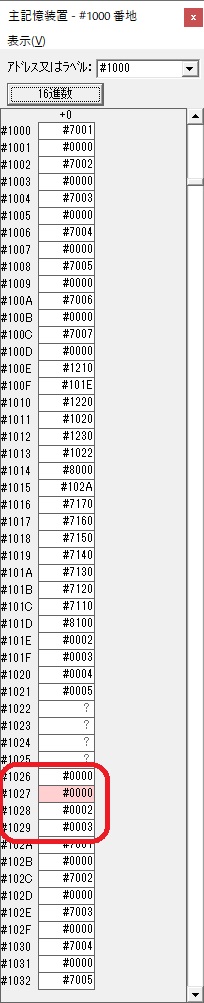
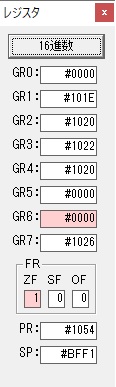
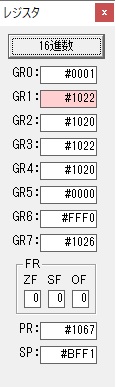
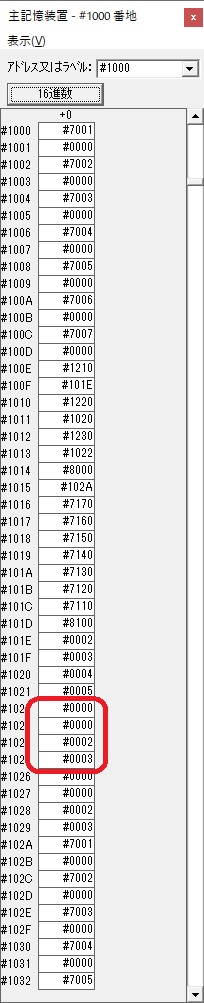
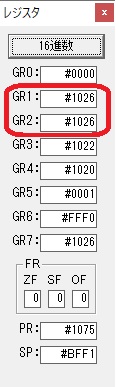
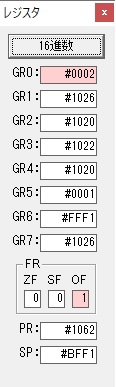
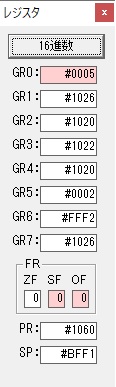
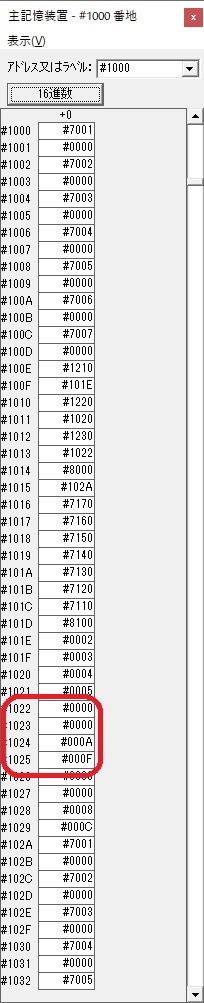
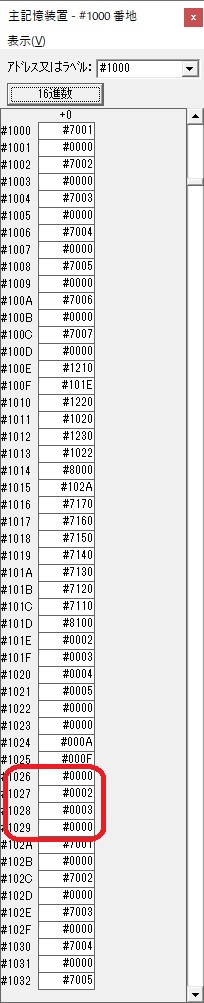
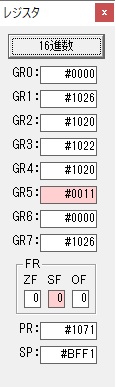
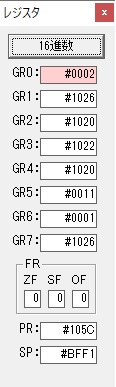
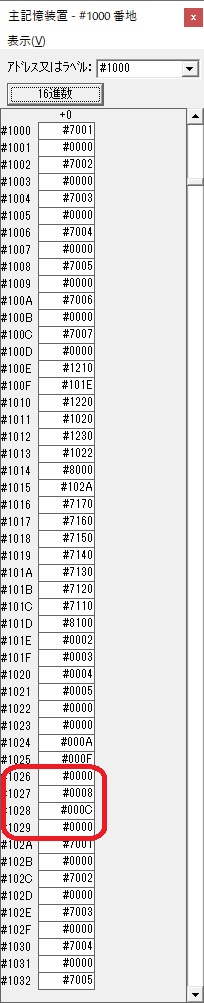
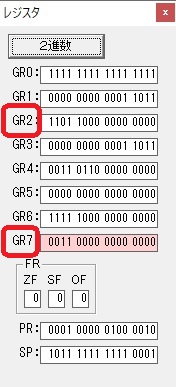
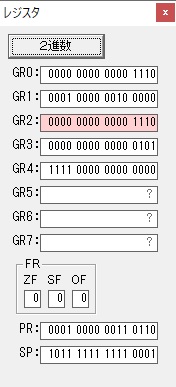
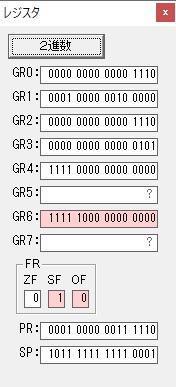
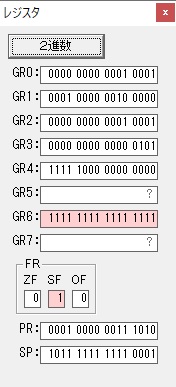
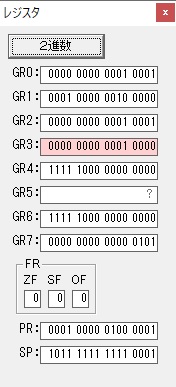
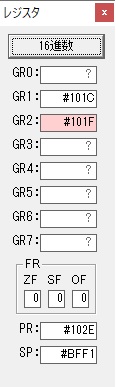
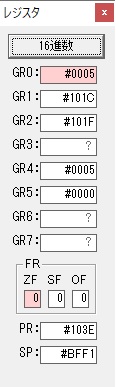
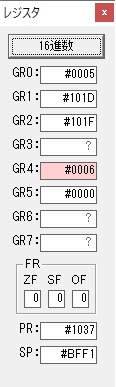
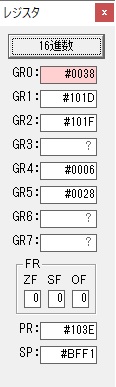
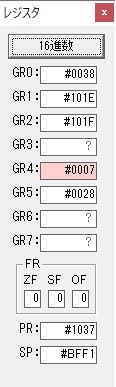
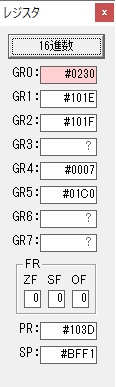
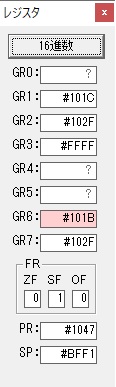
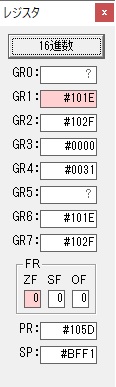
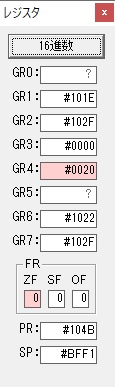
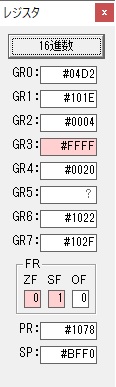
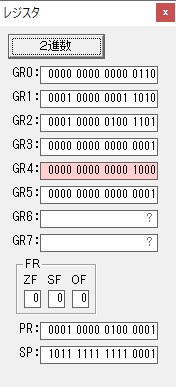
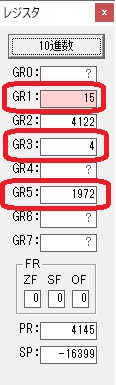
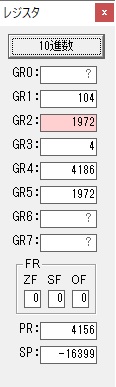
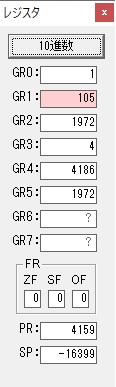
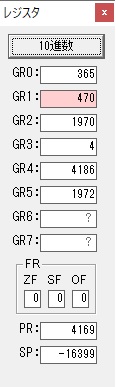
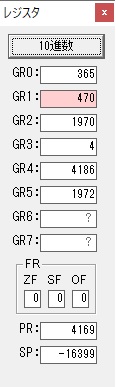
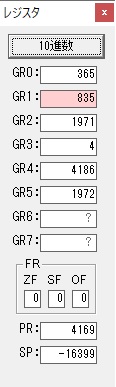
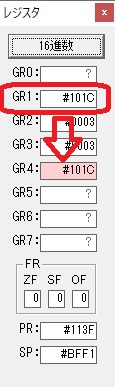
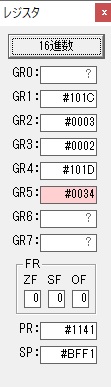
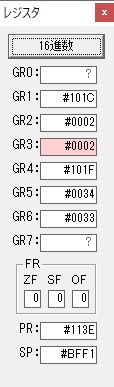
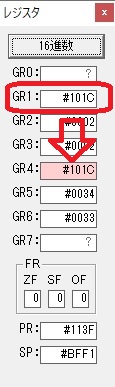
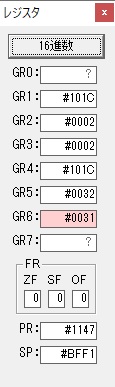
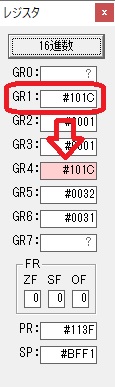
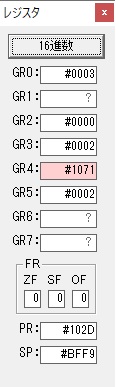
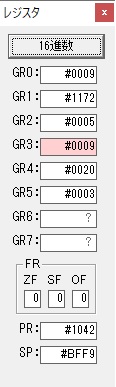
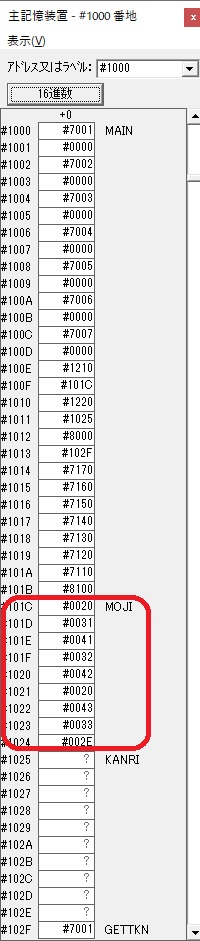
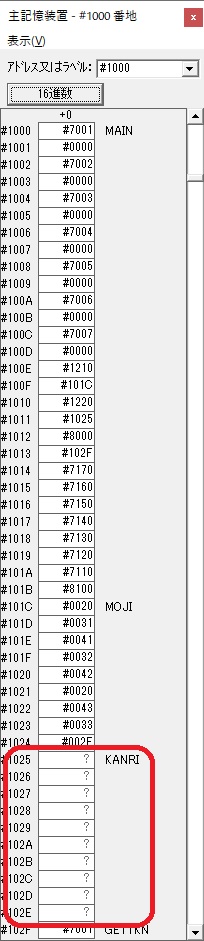
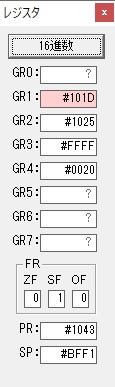
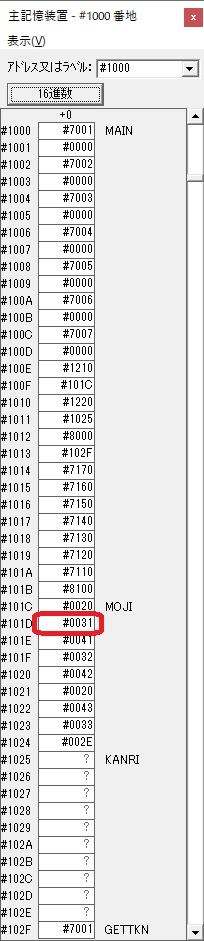
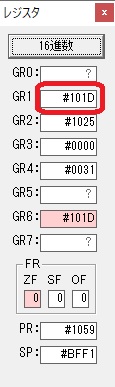
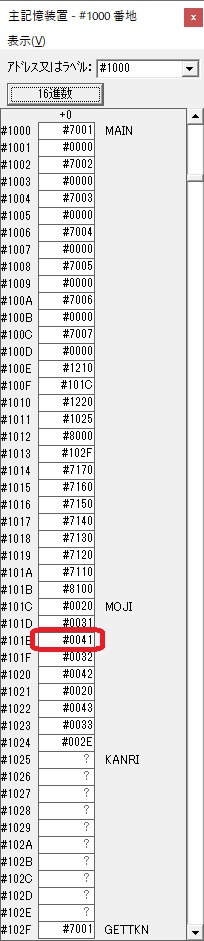
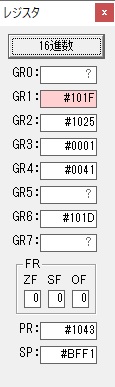
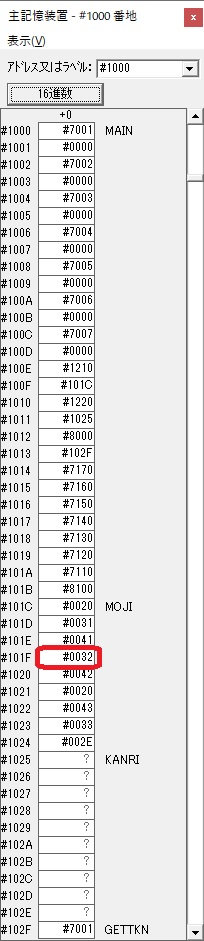
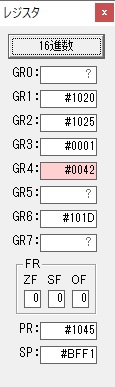
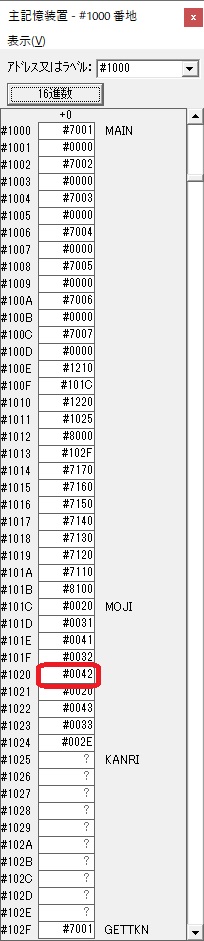
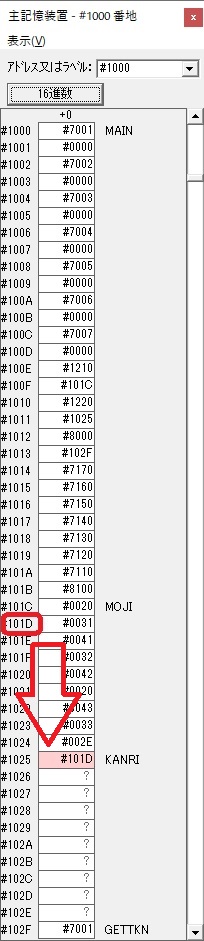
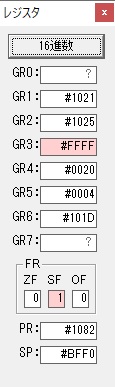
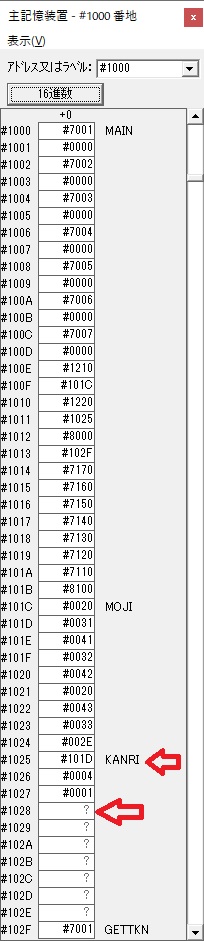
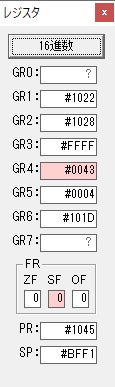
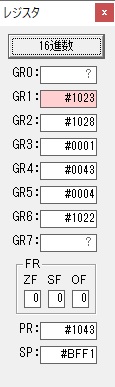
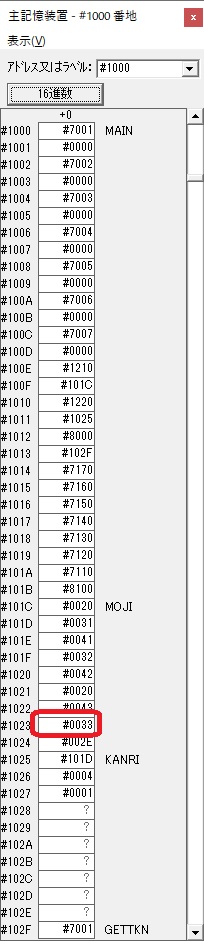
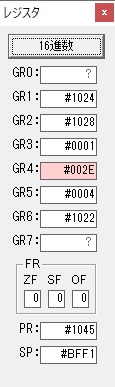
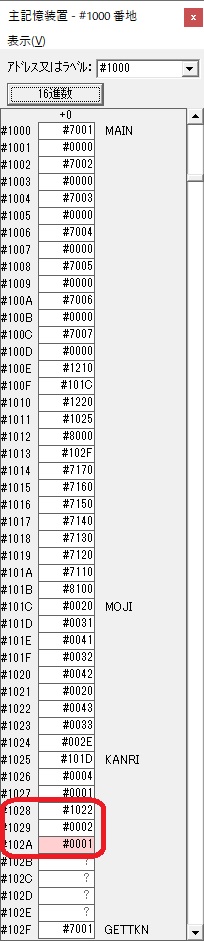
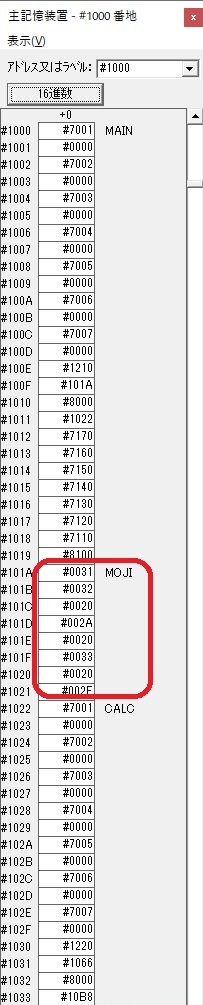
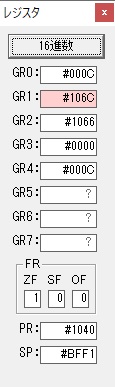
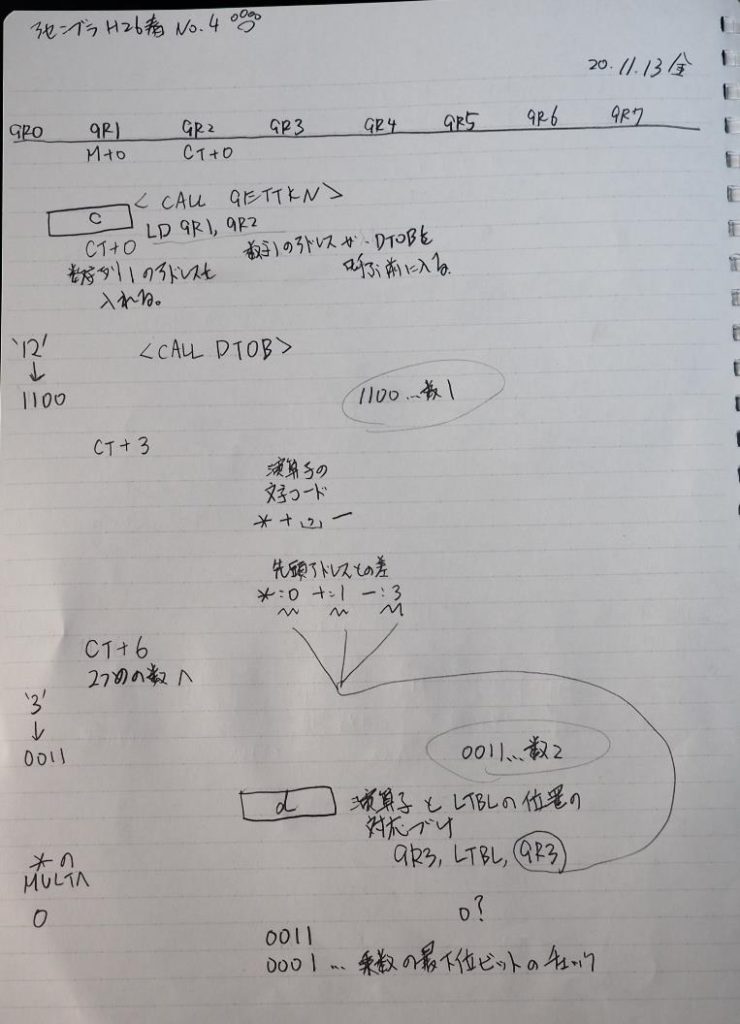
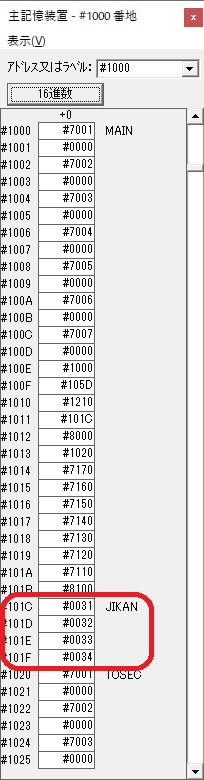
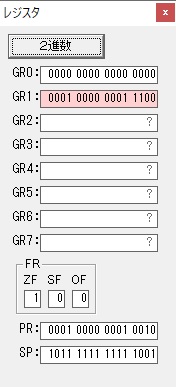
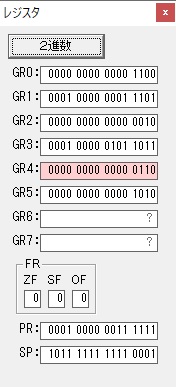
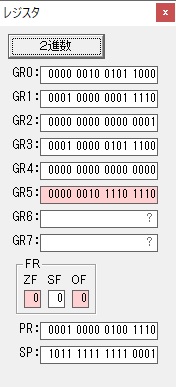
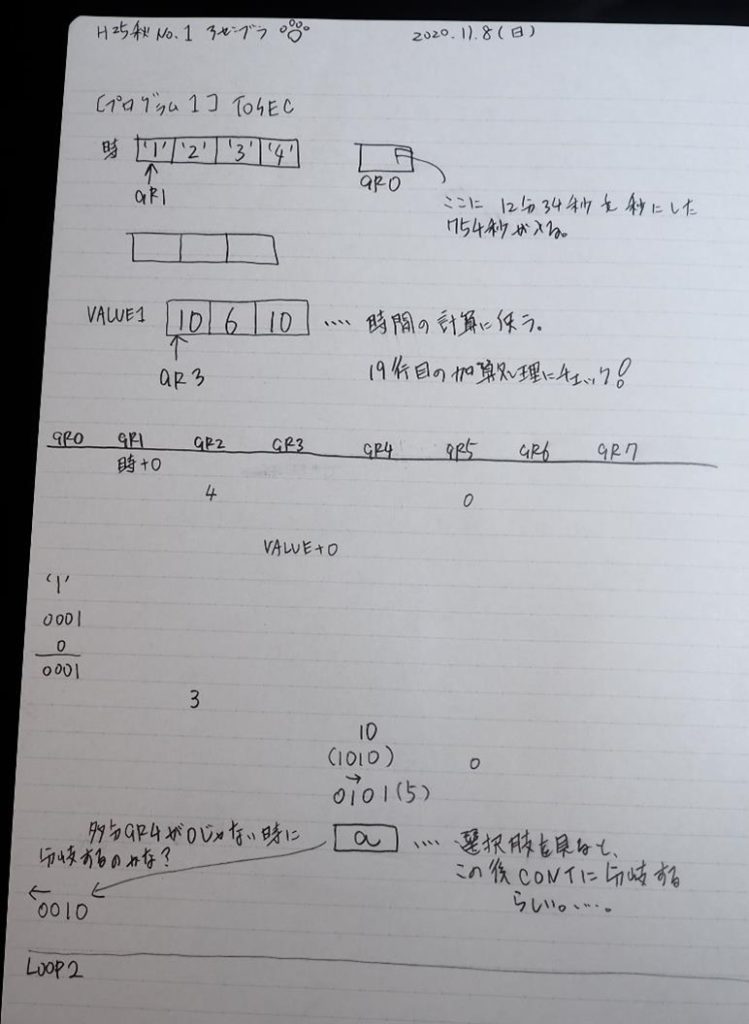
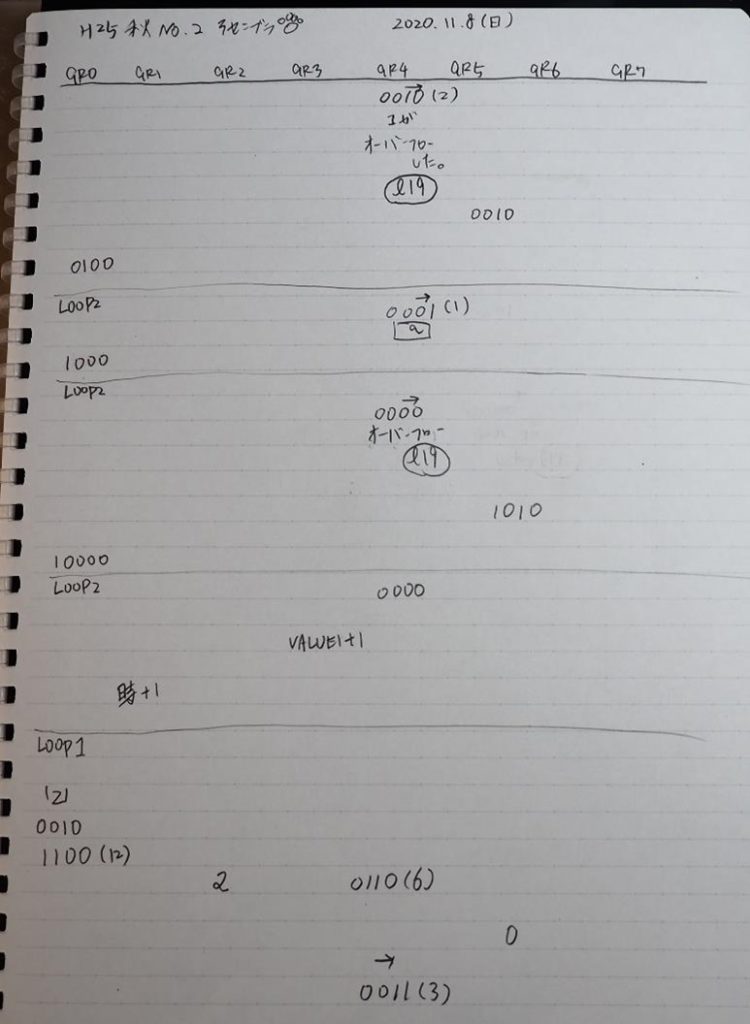
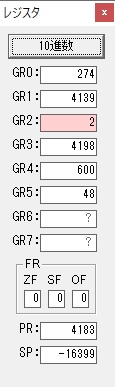
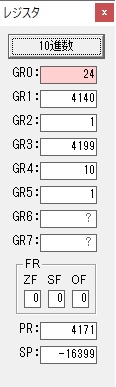
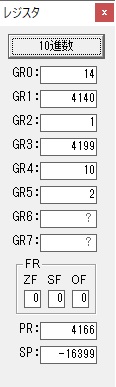
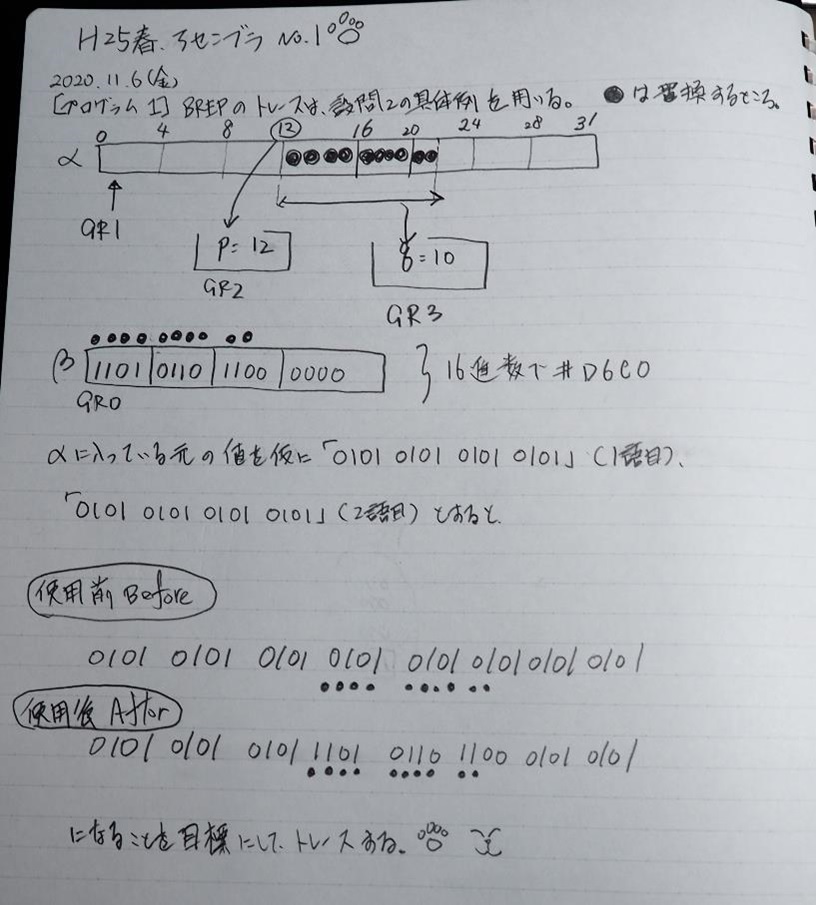
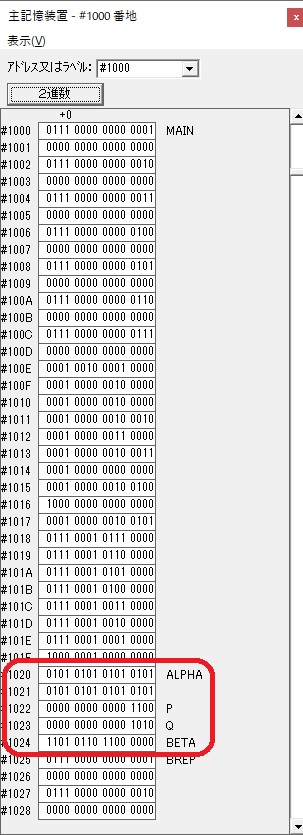
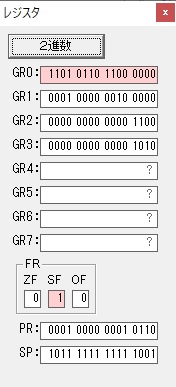
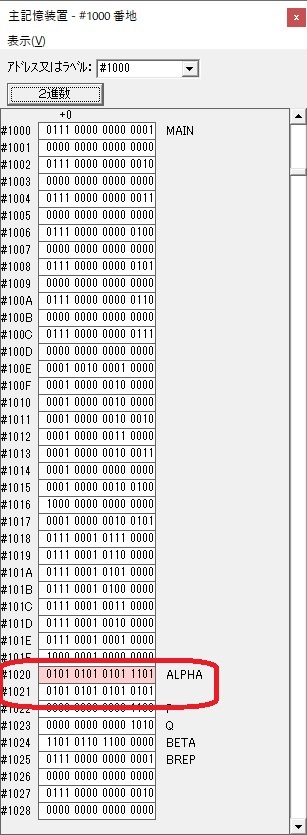
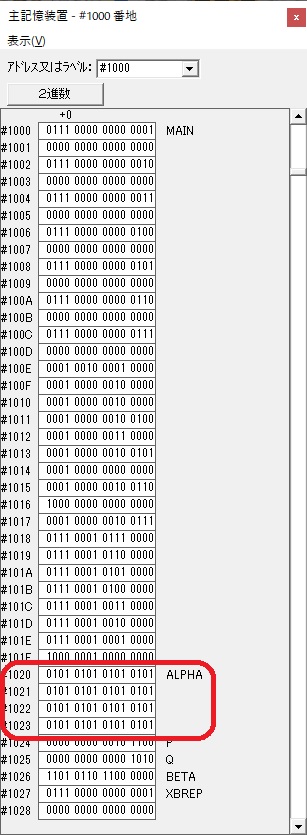
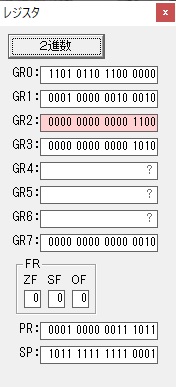
主プログラムを呼び出して、主記憶のJIKANに数字列「1234」が1つずつ入りました。
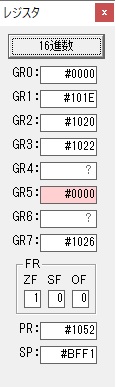
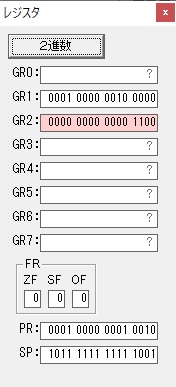
レジスタGR0に0、GR1に数字列JIKANの先頭アドレスが入りました。
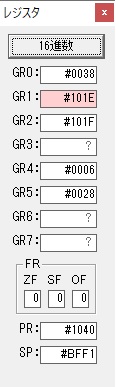
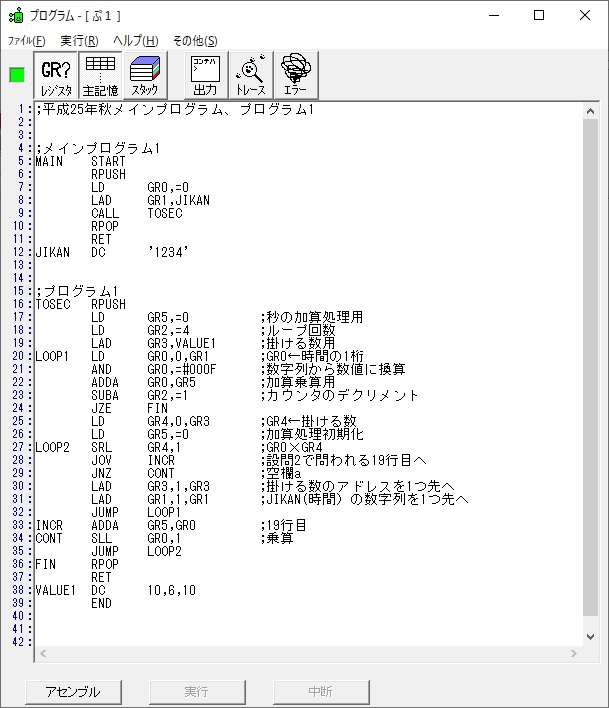
プログラム1のTOSECが呼び出されました。
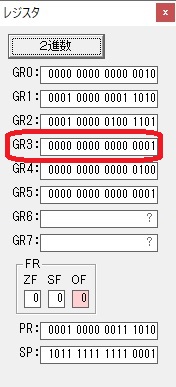
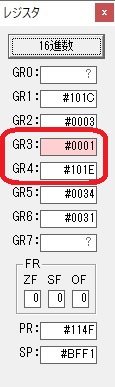
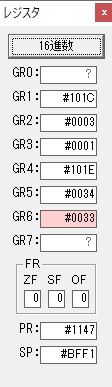
秒に換算するのに使うVALUE1の先頭アドレスがGR3に入りました。
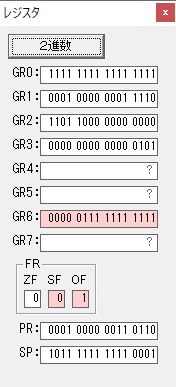
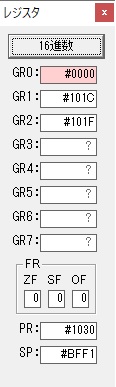
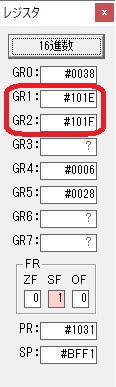
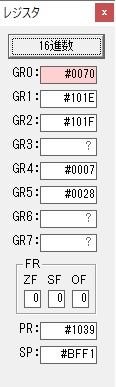
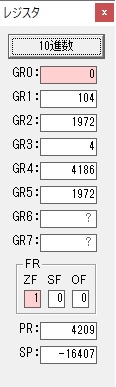
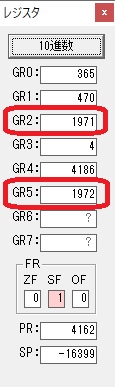
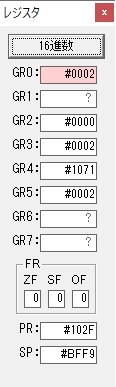
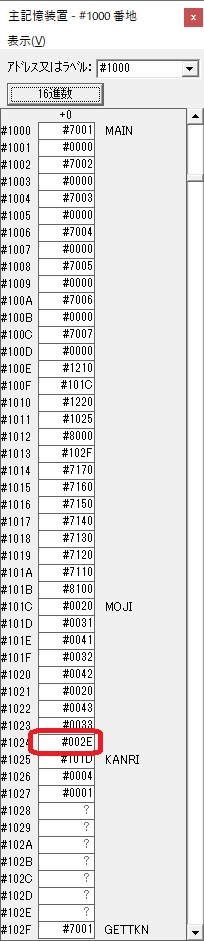
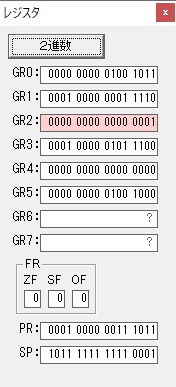
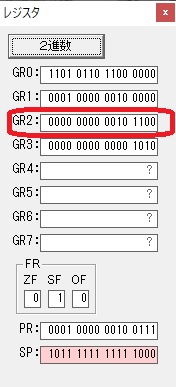
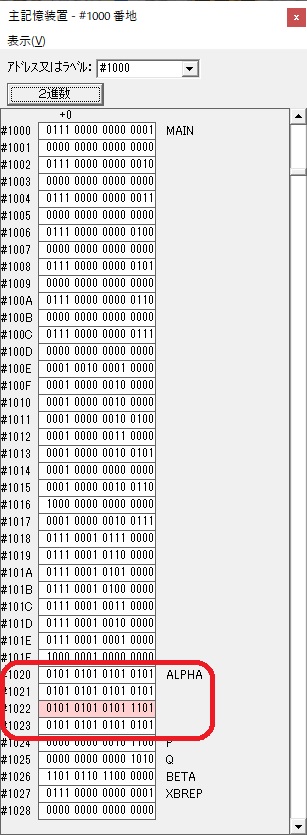
AND演算で数字列0031が1と数値に変換されました。
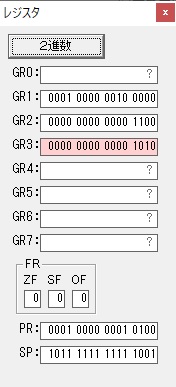
GR2の所で、桁数カウンタが4から3になりました。
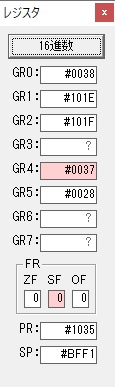
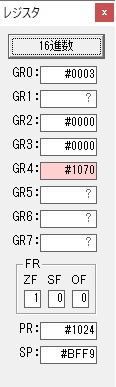
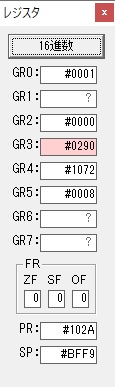
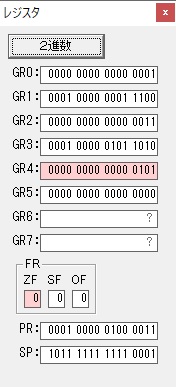
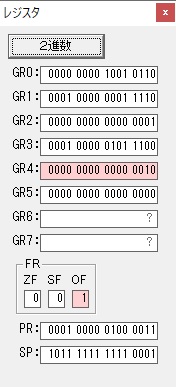
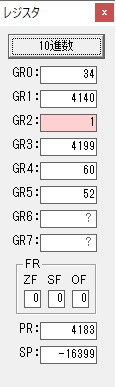
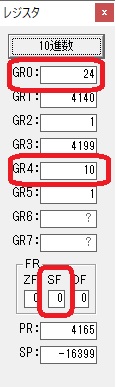
GR4に秒数換算で10倍するのに使う10が入りました。
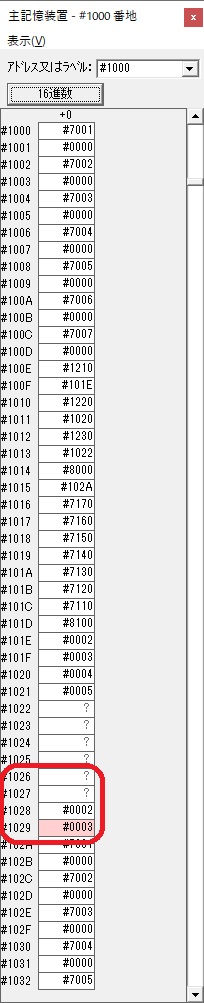
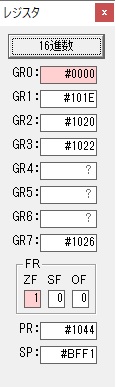
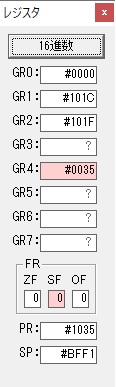
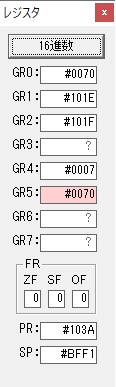
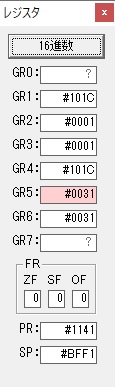
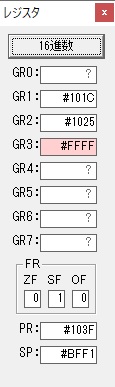
GR4で10倍の10が右シフトされて5倍になりました。
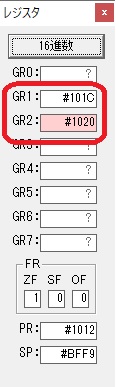
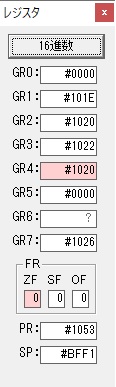
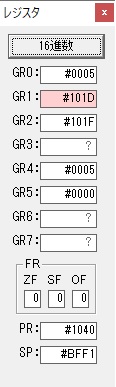
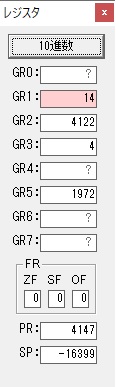
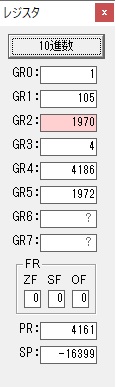
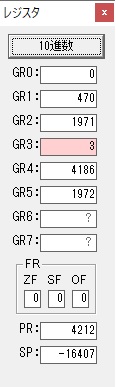
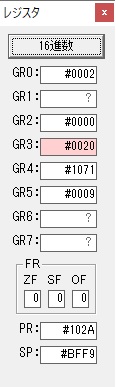
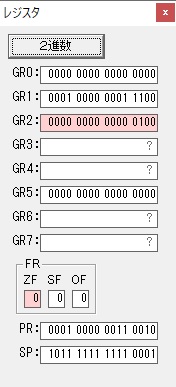
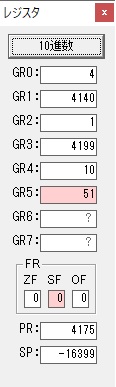
GR0で数値の1が2になりました。
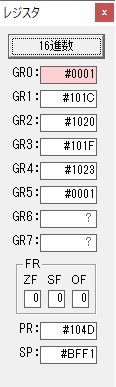
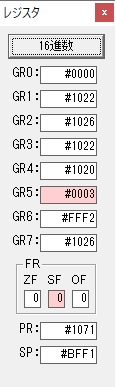
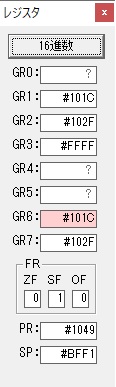
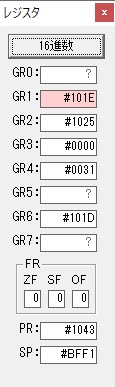
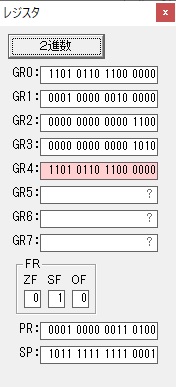
ループ2へ
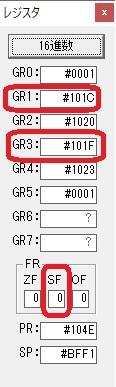
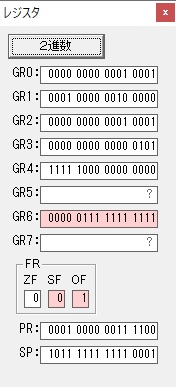
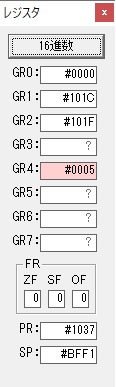
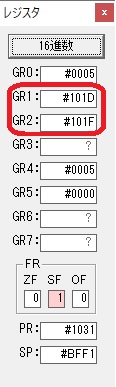
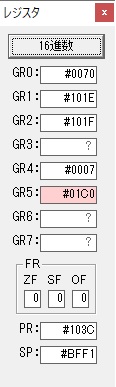
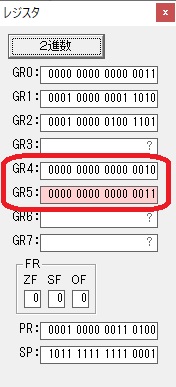
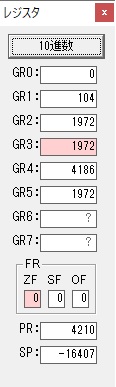
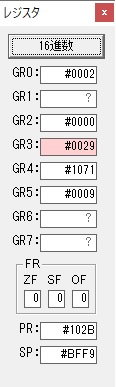
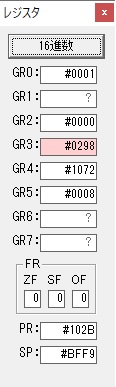
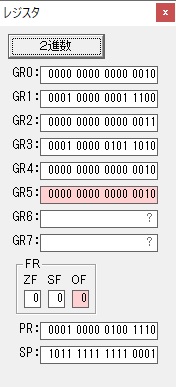
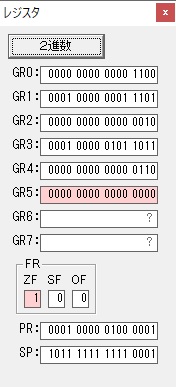
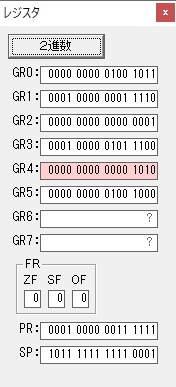
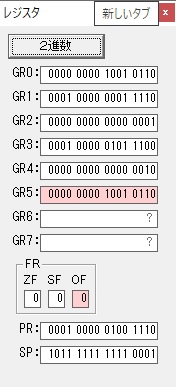
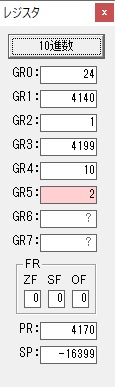
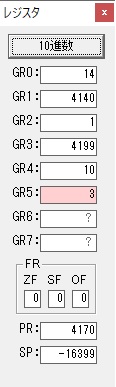
GR4で掛ける数の5倍から2倍になりました。
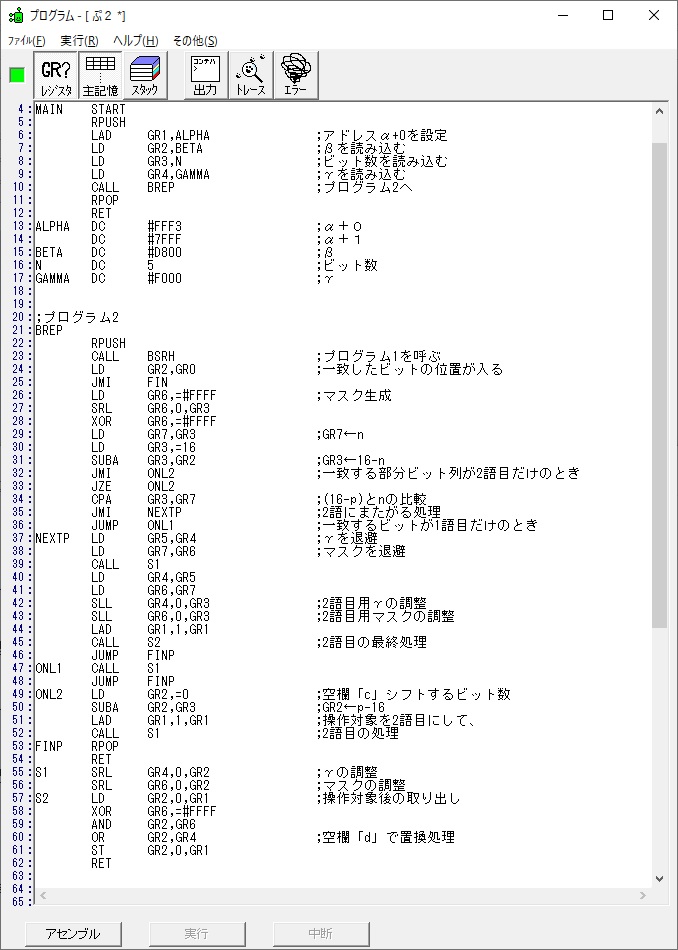
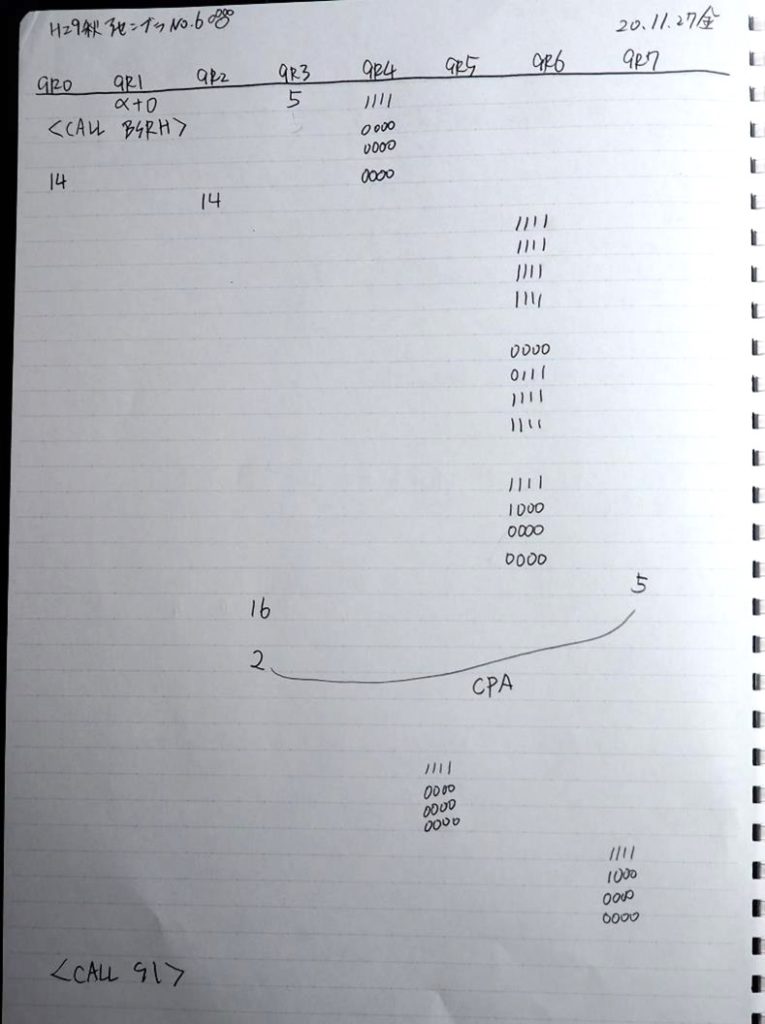
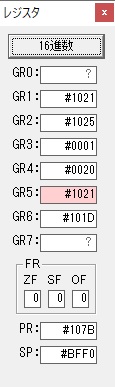
GR5に1×2=2が加算されました・・・19行目が1回目
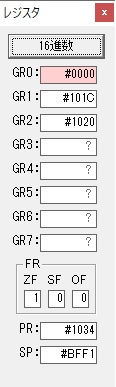
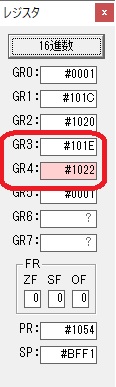
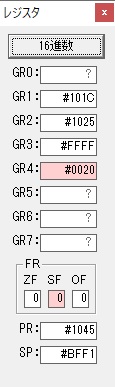
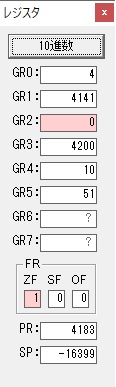
GR0に数値2が更に2倍されて4になりました。
ループ2へ
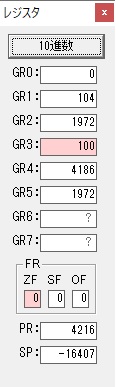
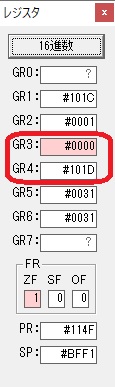
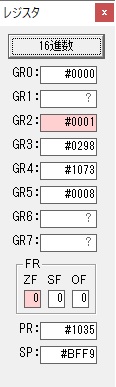
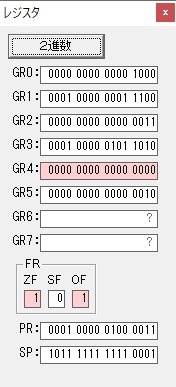
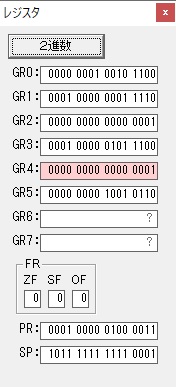
GR4でかける数2倍が右シフトされて1倍になりました。
GR0で数値4が2倍されて8になりました。
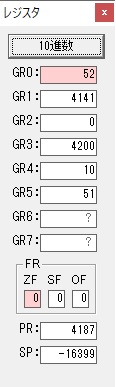
ループ2へ
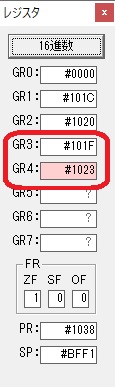
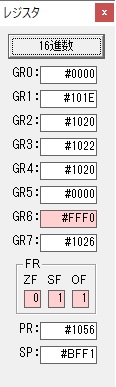
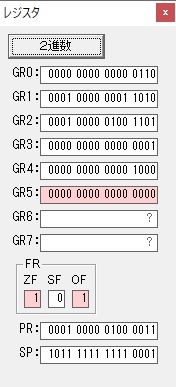
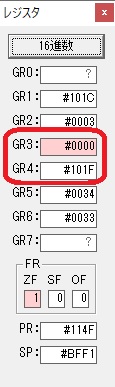
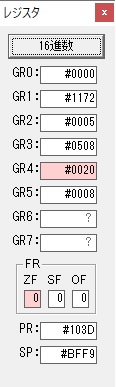
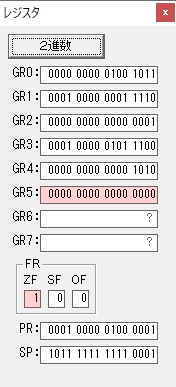
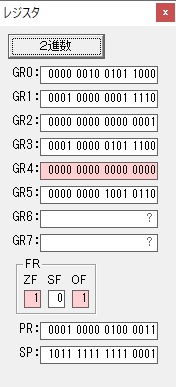
GR4で1倍が右シフトされ0になりました。
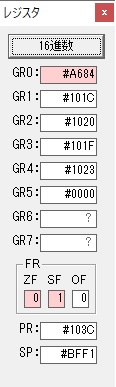
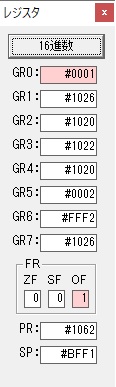
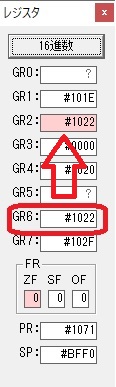
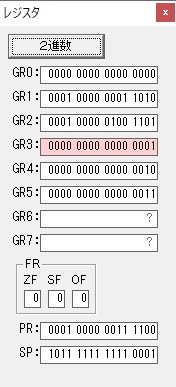
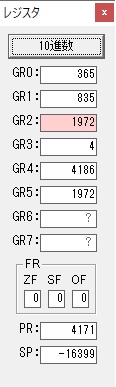
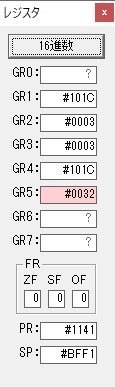
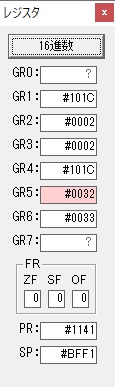
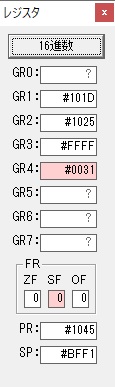
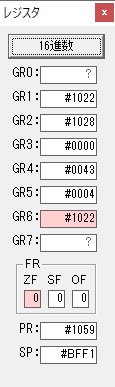
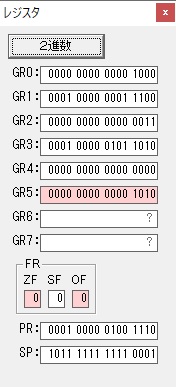
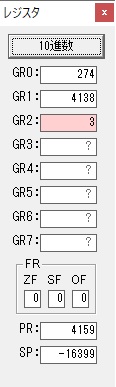
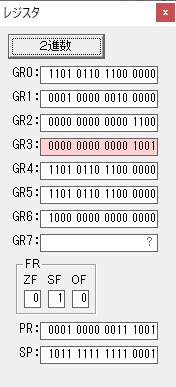
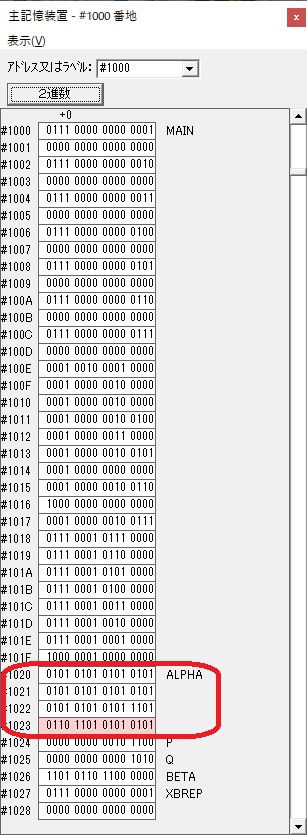
GR5の2倍とGR0の8倍が加算されGR5の所で10倍になります。・・・19行目が2回目
GR0が2倍され16になりますが、これは後で次の数字列に上書きされます。
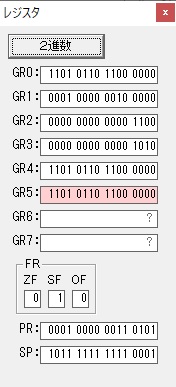
ループ2へ
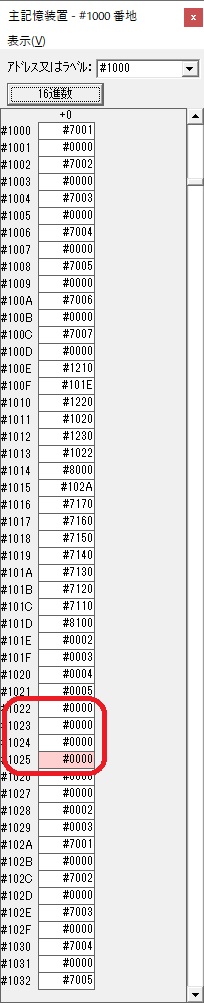
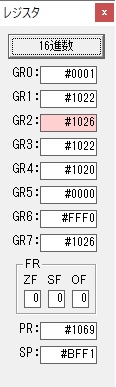
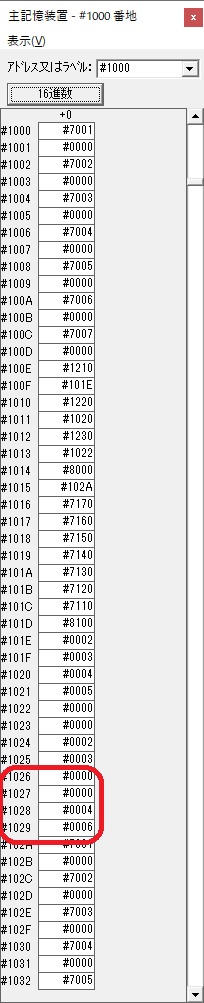
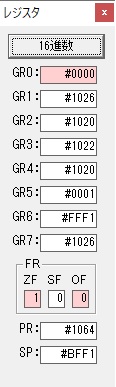
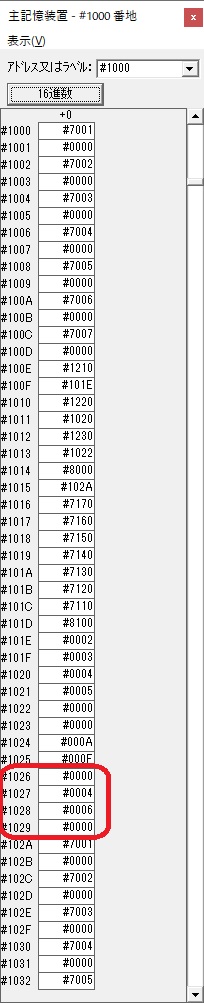
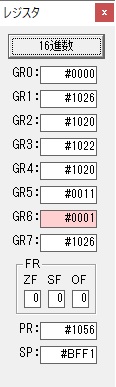
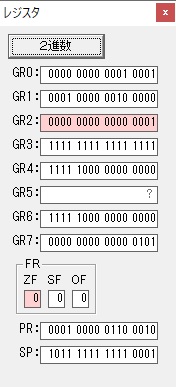
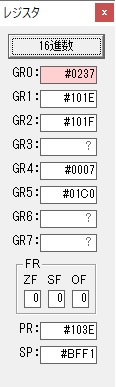
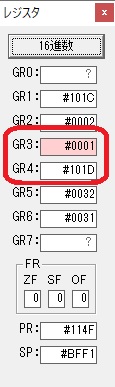
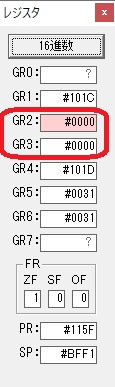
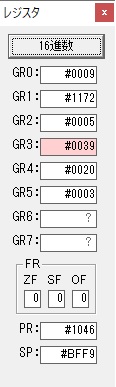
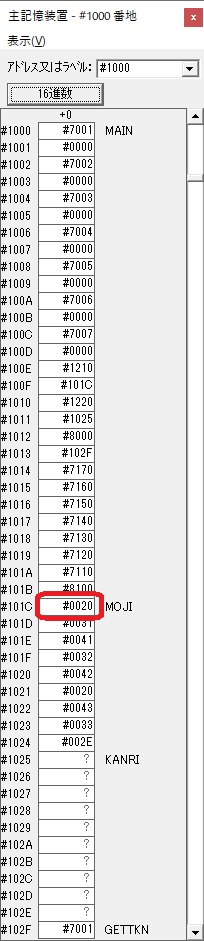
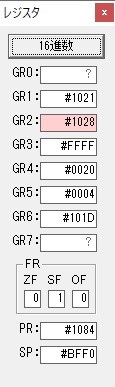
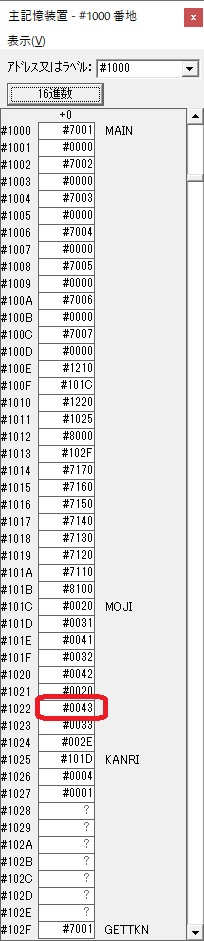
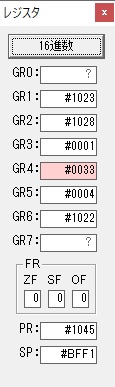
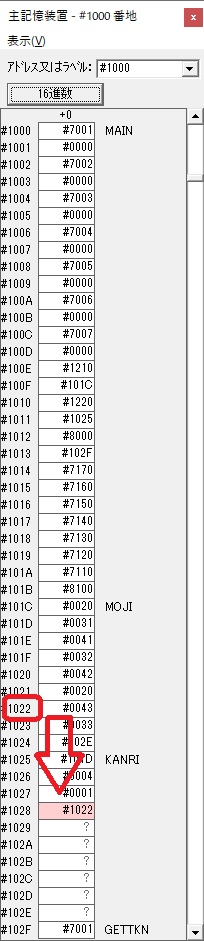
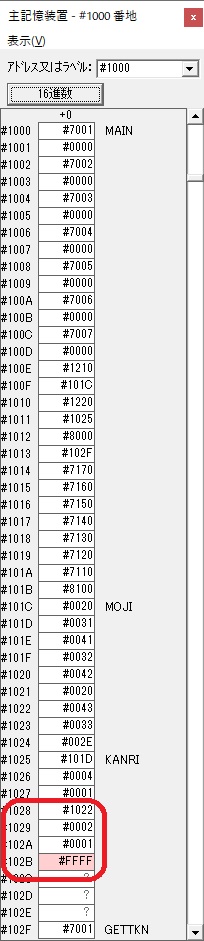
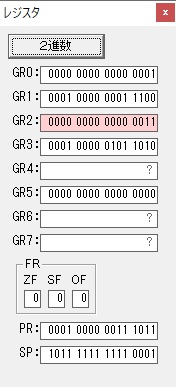
GR3でVAUE1、GR1でJIKANのアドレスが1つ先に進んで次の数字列の処理に入ります。
ループ1へ
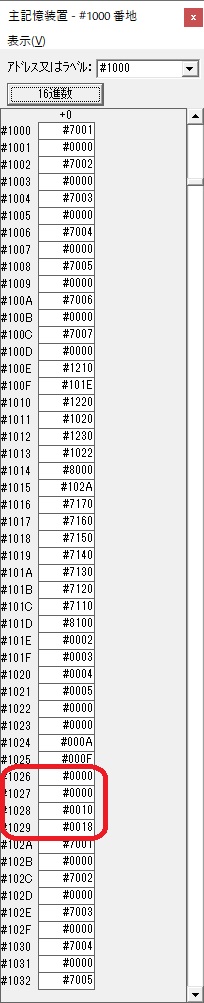
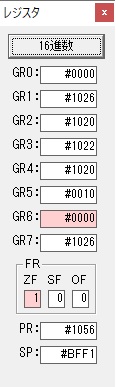
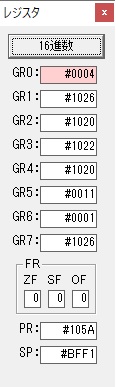
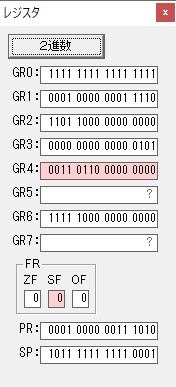
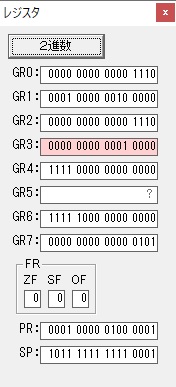
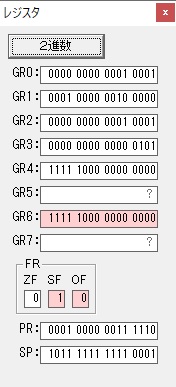
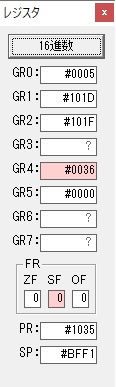
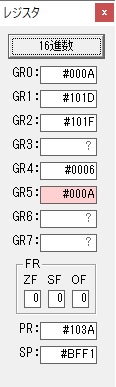
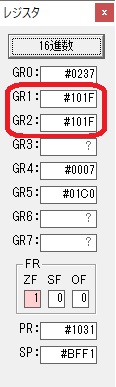
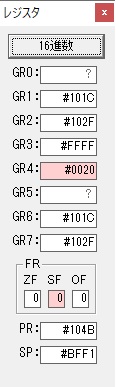
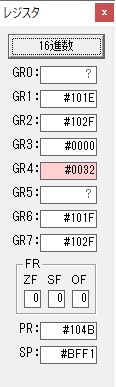
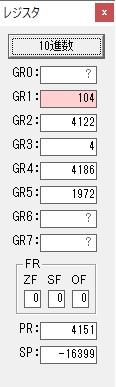
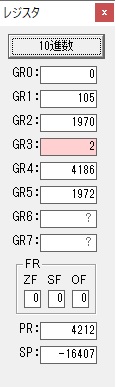
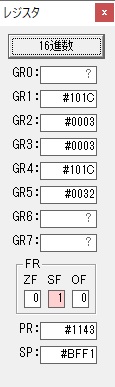
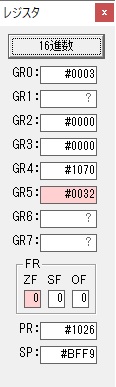
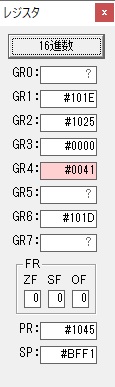
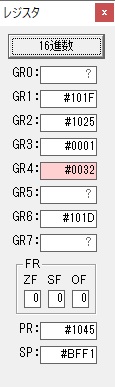
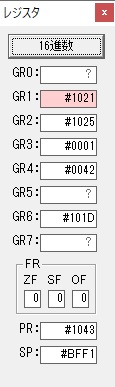
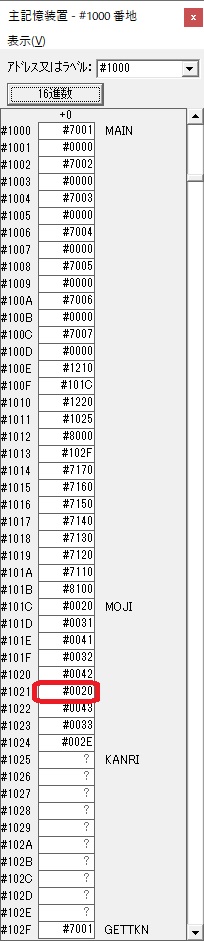
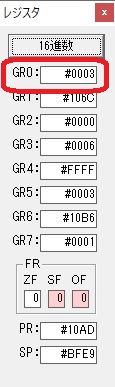
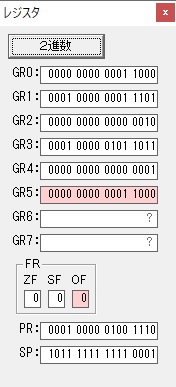
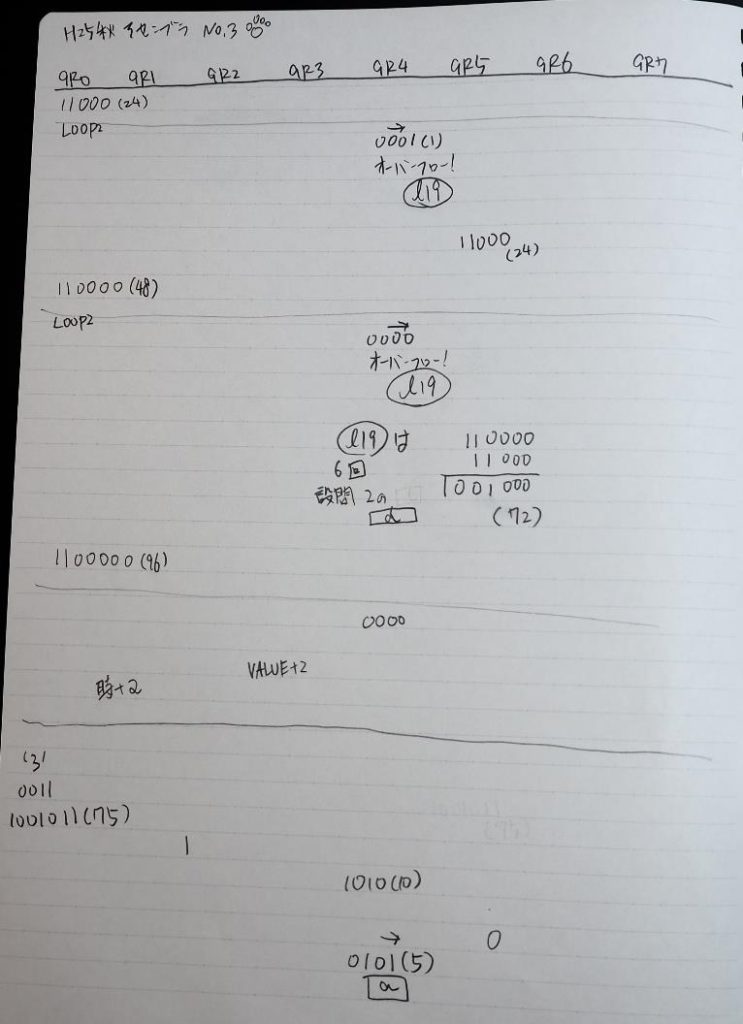
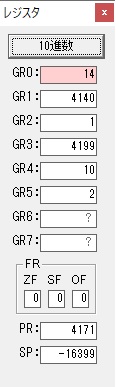
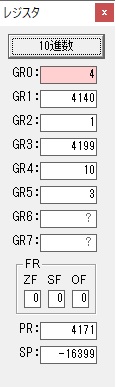
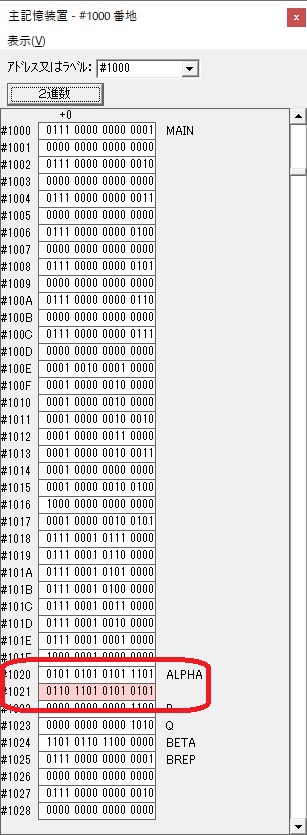
GR0に数字列「2」の0032が読み込まれました。
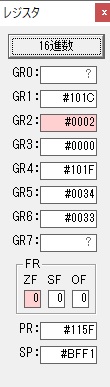
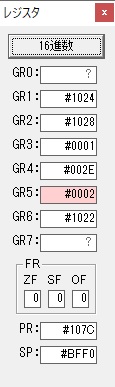
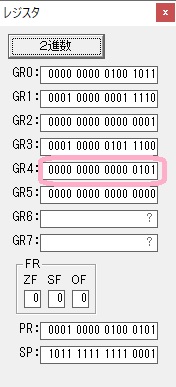
数値の2に変換されました。
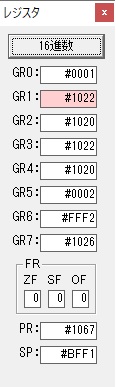
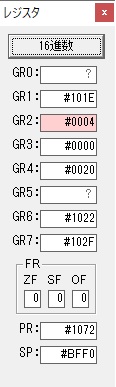
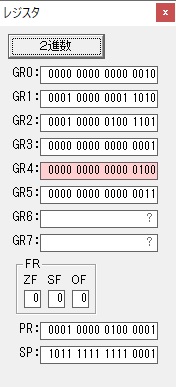
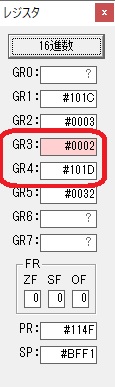
GR0にGR0の2とGR510が加算され、12になりました。
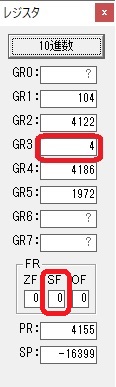
GR2の桁数のカウントが1つ減りました。
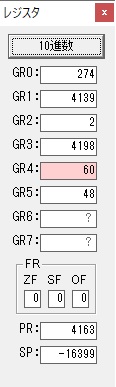
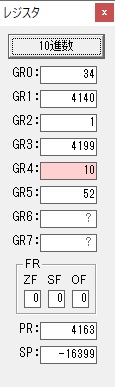
GR4にVALUE1のかける数6が読み込まれました。
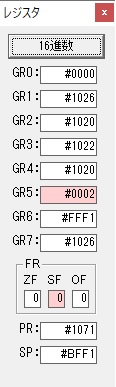
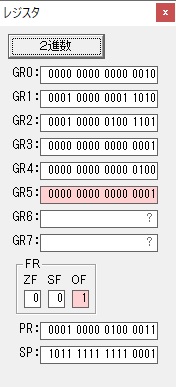
計算の為にGR5が初期化されました。
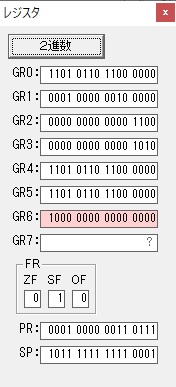
ループ2
GR4のかける数が右シフトで6から3になりました。
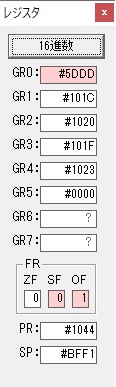
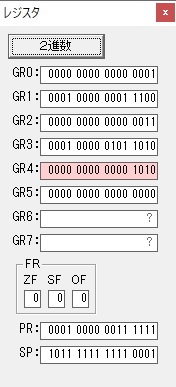
GR0で12が2倍され24になりました。
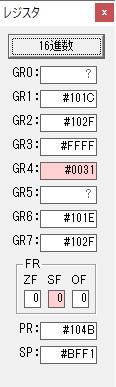
ループ2へ
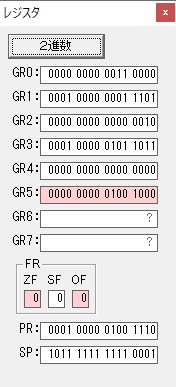
かける数が3から1に右シフトされました。
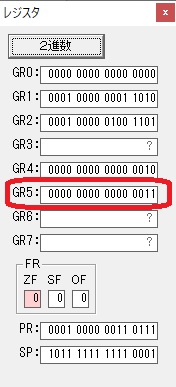
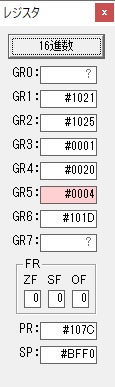
GR5に24が加算されました。・・・19行目が3回目
GR0が2倍され48になりました。
ループ2
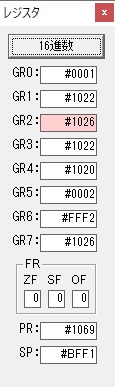
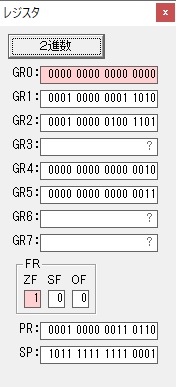
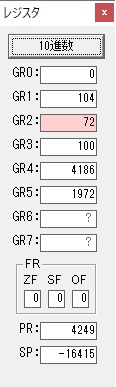
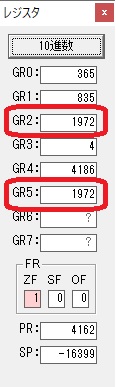
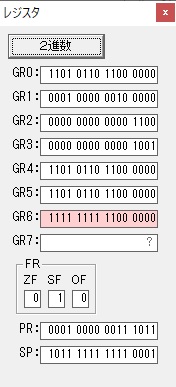
GR5の24ににGR0の48が加算されて、72になりました。・・・19行目が4回目
GR0が2倍されますが、これは次の数字列に上書きされます。
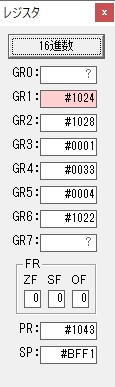
ループ1へ
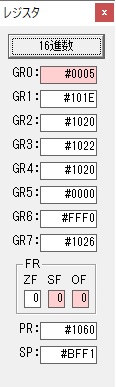
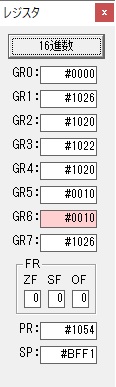
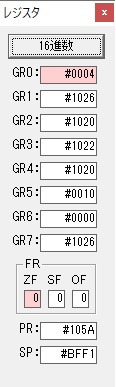
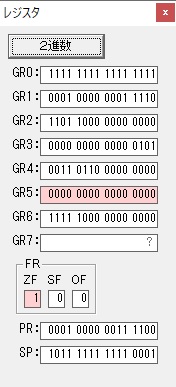
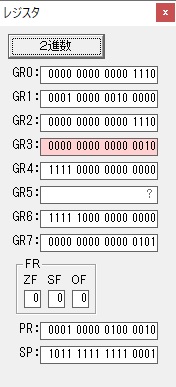
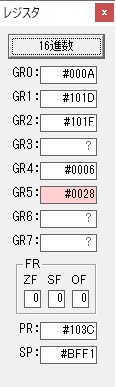
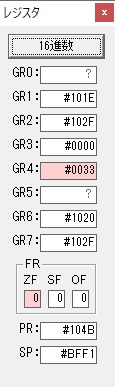
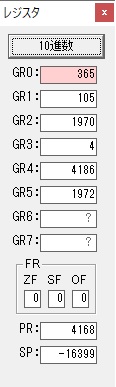
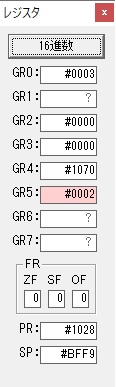
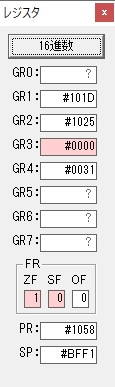
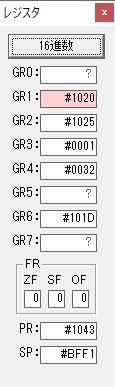
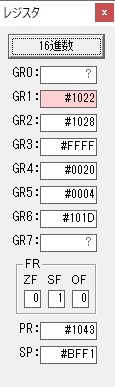
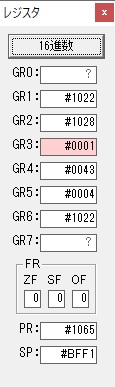
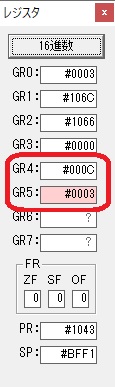
GR0の数字列「3」の0033が入りました。
数字列0033から数値の3に換算されました。
GR0にGR0の3とGR5の72が加算されて75になりました。
GR2で桁数のカウンタが2から1に減りました。
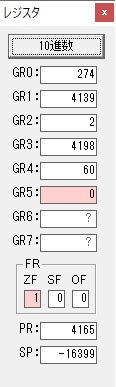
GR4にかける数10倍の10が入りました。
75を10倍する為の計算用レジスタGR5が初期化されました。
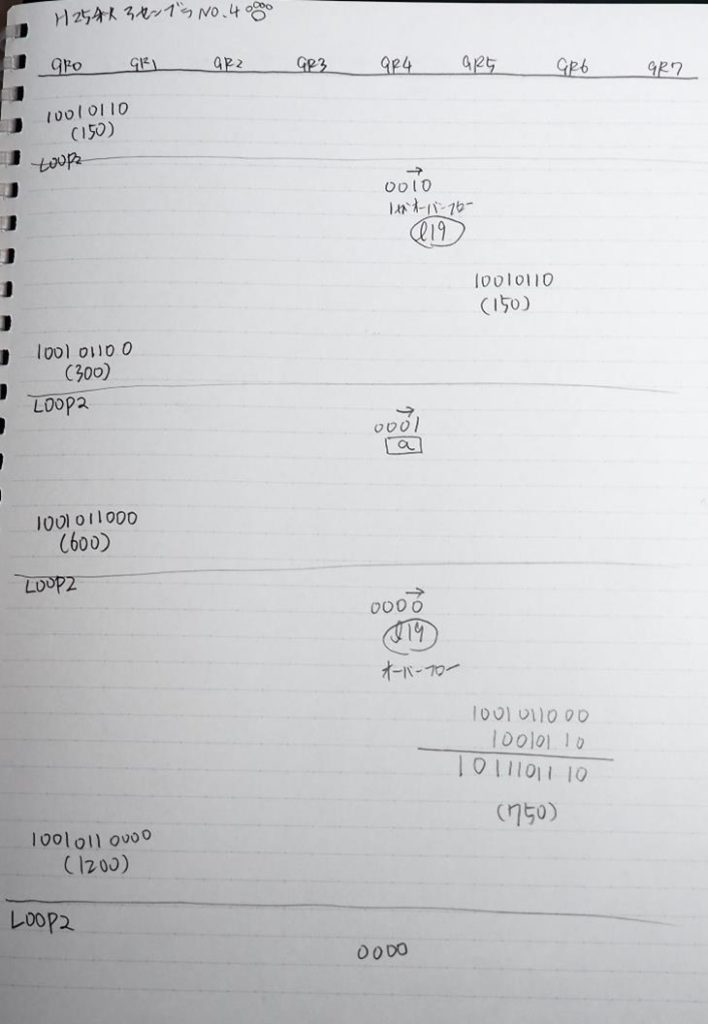
GR4でかける数の10倍が右シフトされ5倍になりました。
GR0で75が2倍されて150になりました。
ループ2へ
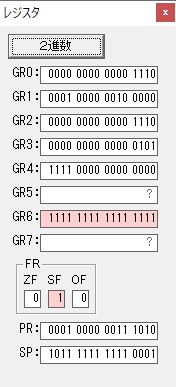
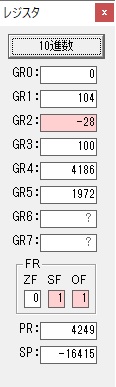
GR4でかける数が5倍から右シフトされ2倍になり、オーバーフローしたので
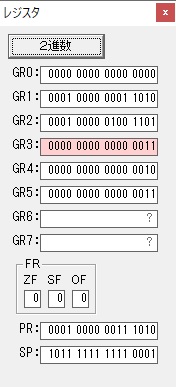
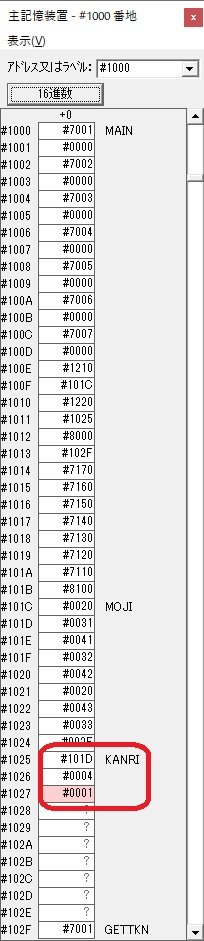
GR5に150が加算されました。・・・19行目が5回目
GR0の150が2倍され300になりました。
ループ2へ
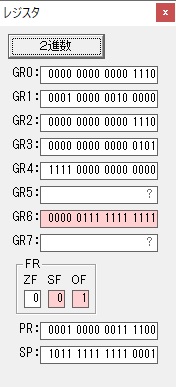
GR4のかける数2倍が右シフトされて、1倍になりました。
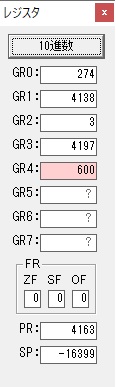
GR0の300が2倍されて600になりました。
ループ2へ
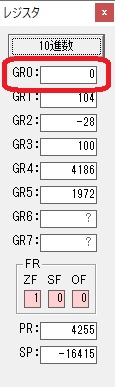
GR5の150にGR0の600が加算されて750になりました。・・・19行目が6回目
GR0が2倍されますが、次の文字が上書きされます。
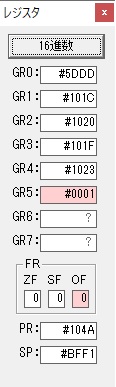
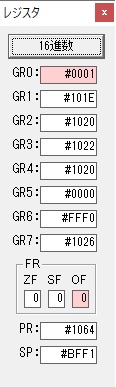
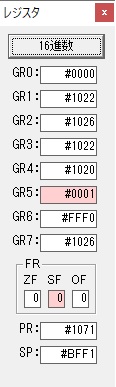
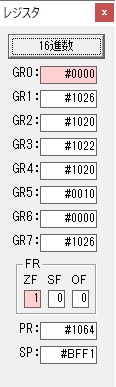
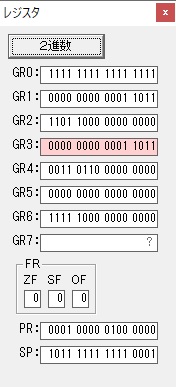
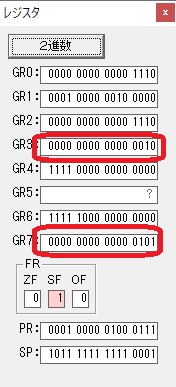
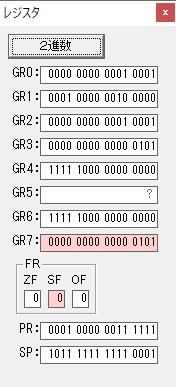
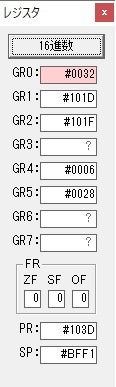
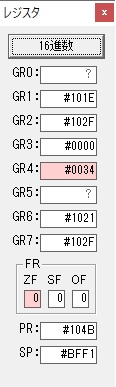
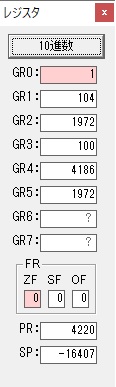
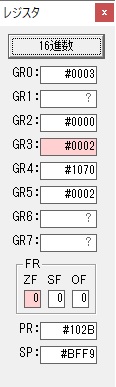
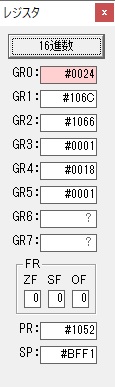
GR0に数字列「4」の0034が読み込まれました。
GR0で数字列4から数値4に変換されました。
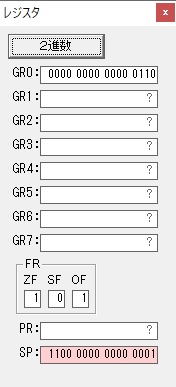
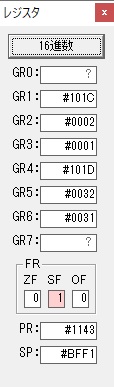
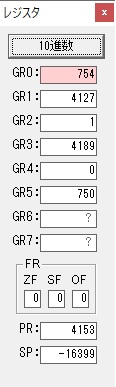
GR0にGR5が加算され754になりました。
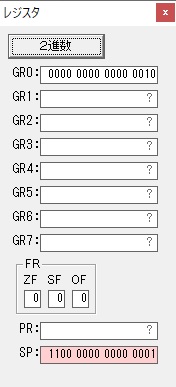
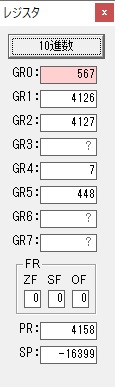
ちょっと数が大きくなったので、10進数表記にします。
また2進数に戻します。
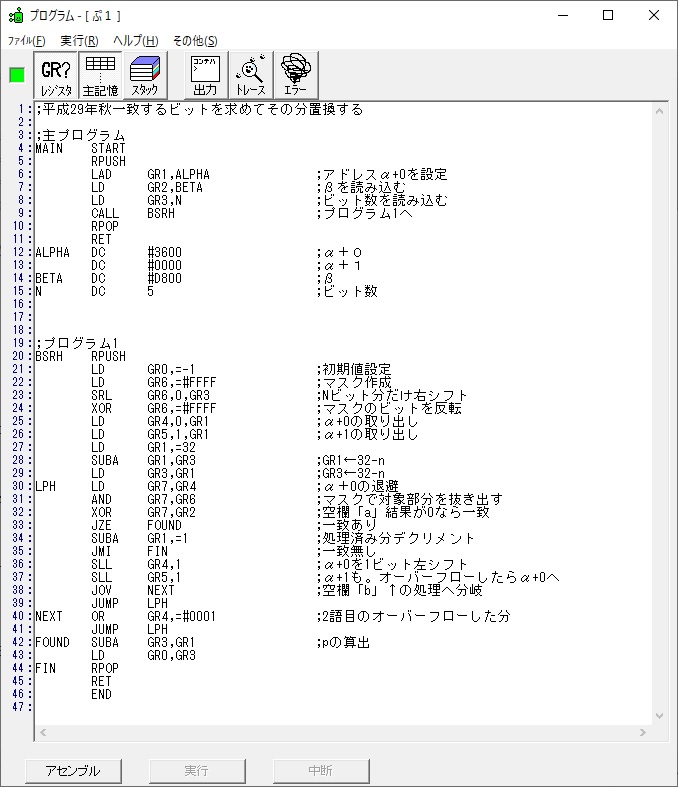
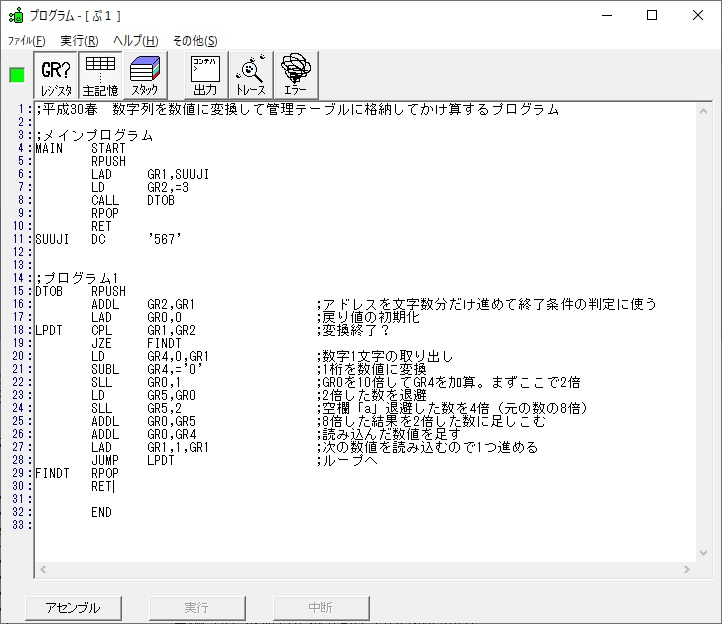
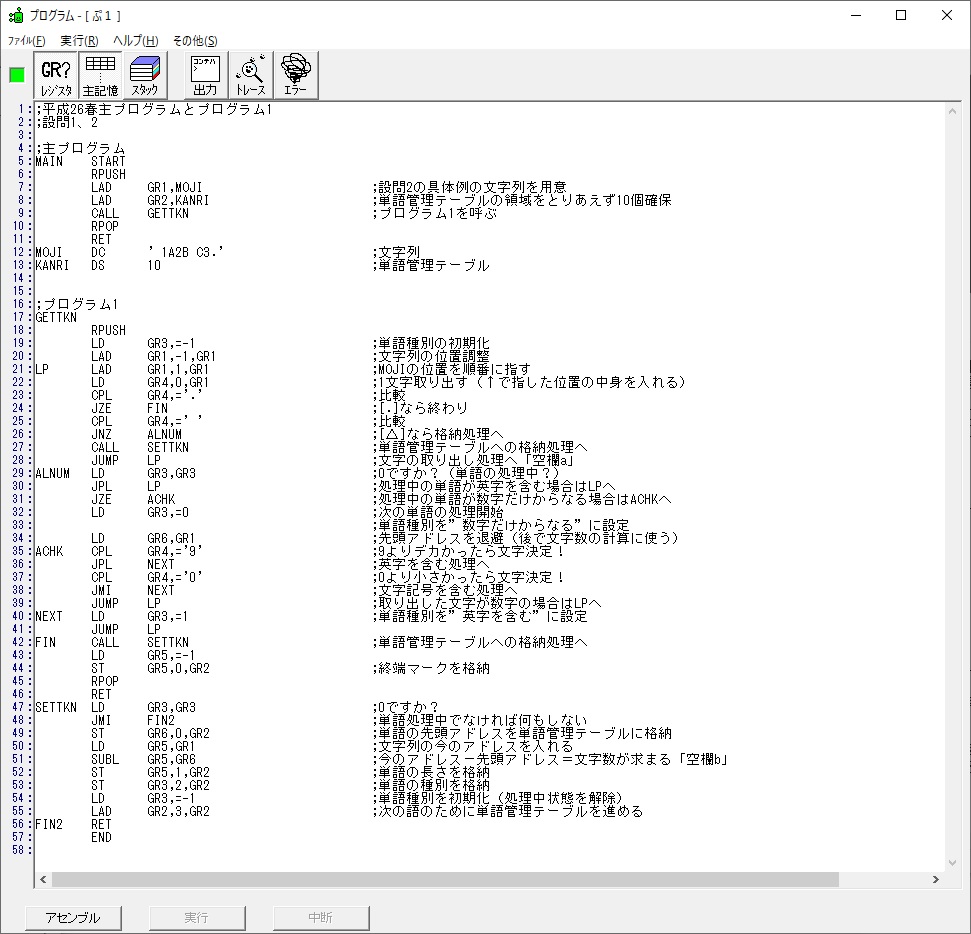
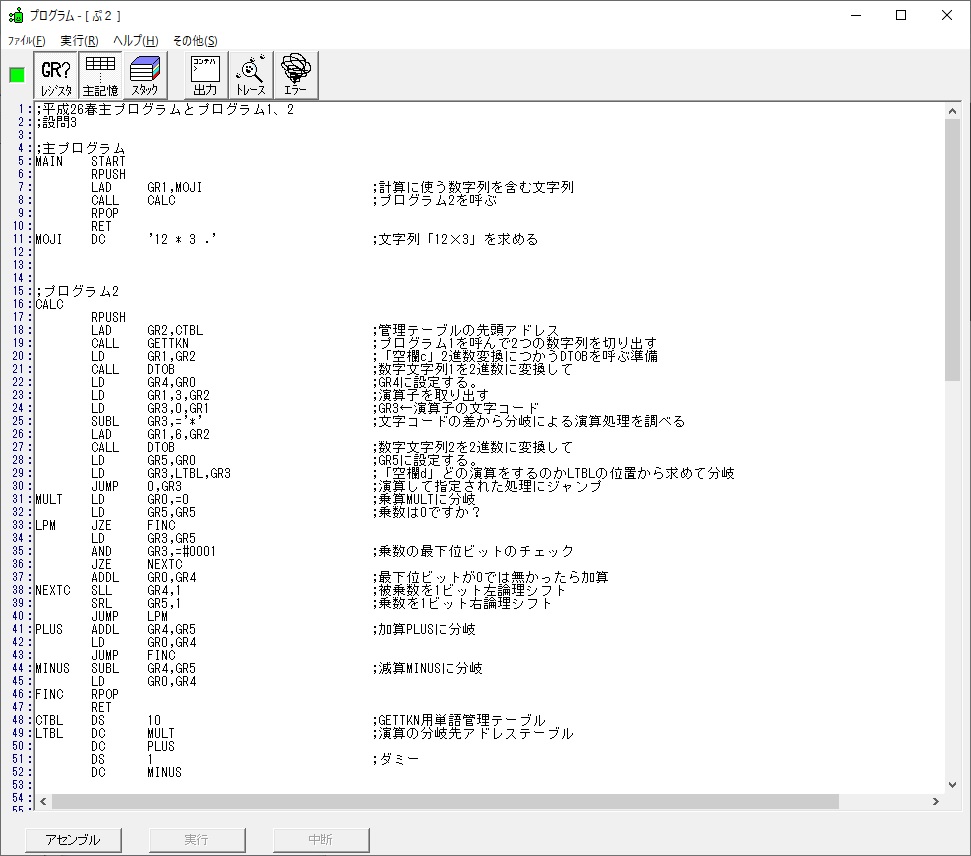
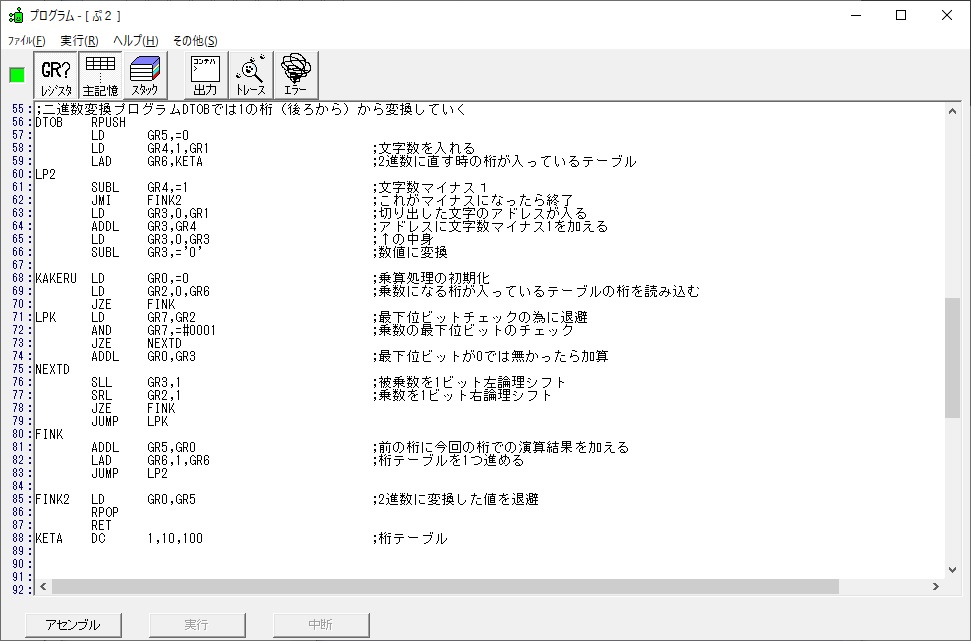
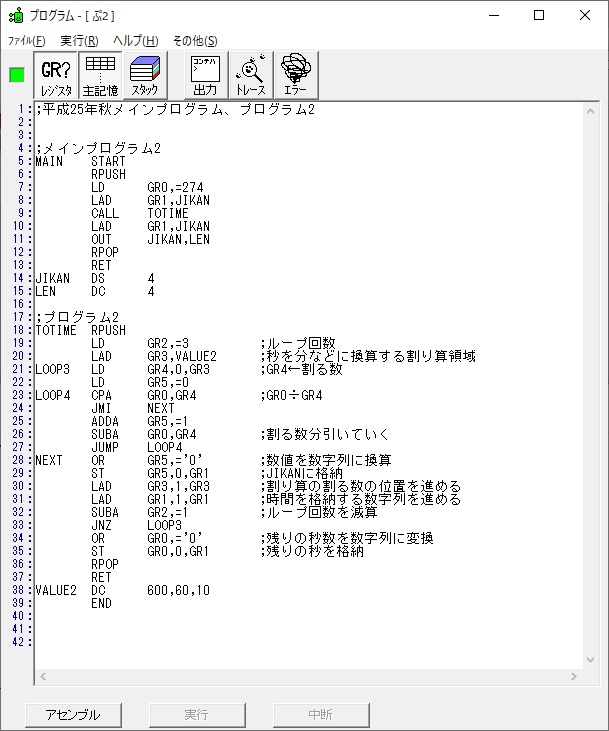
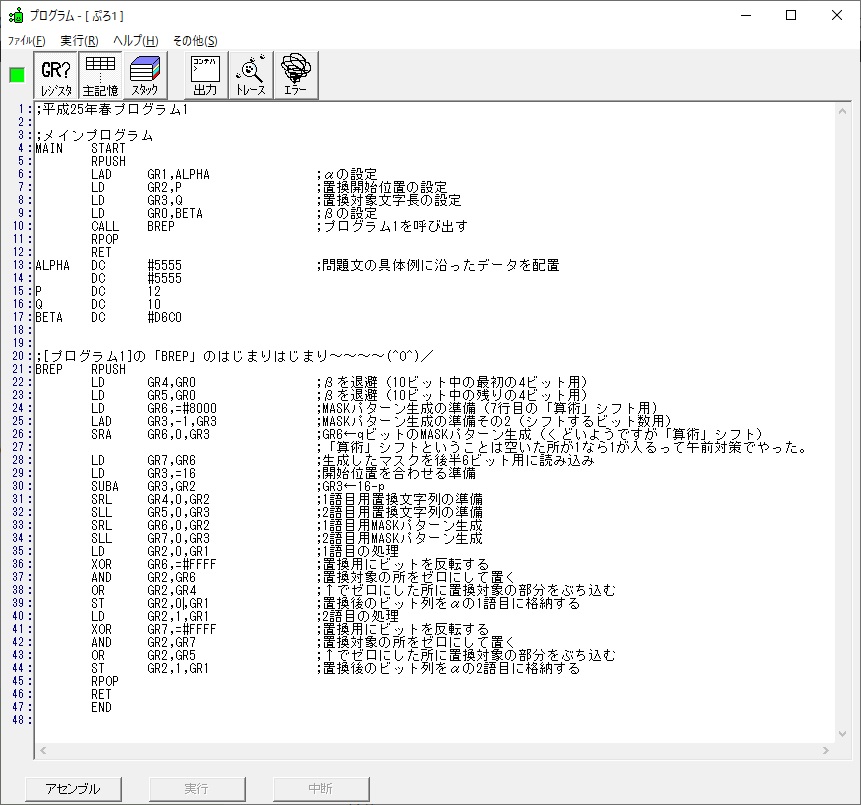
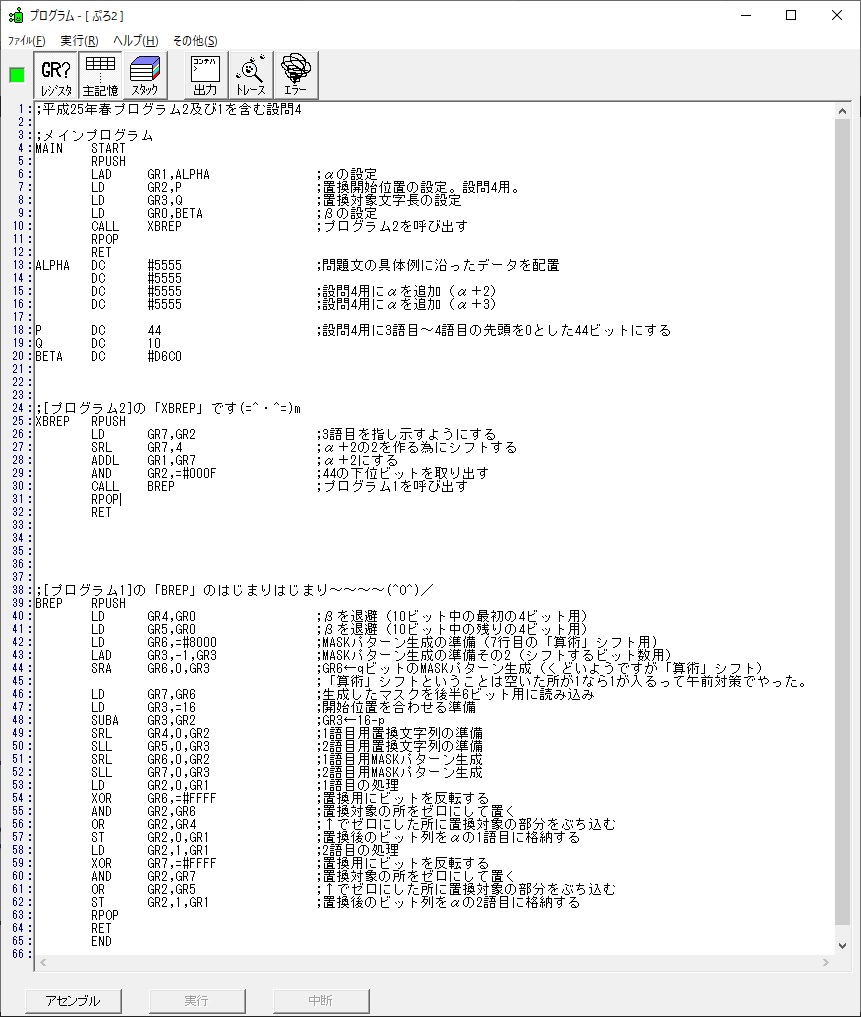
では、プログラム1です。
;平成25年秋メインプログラム、プログラム1
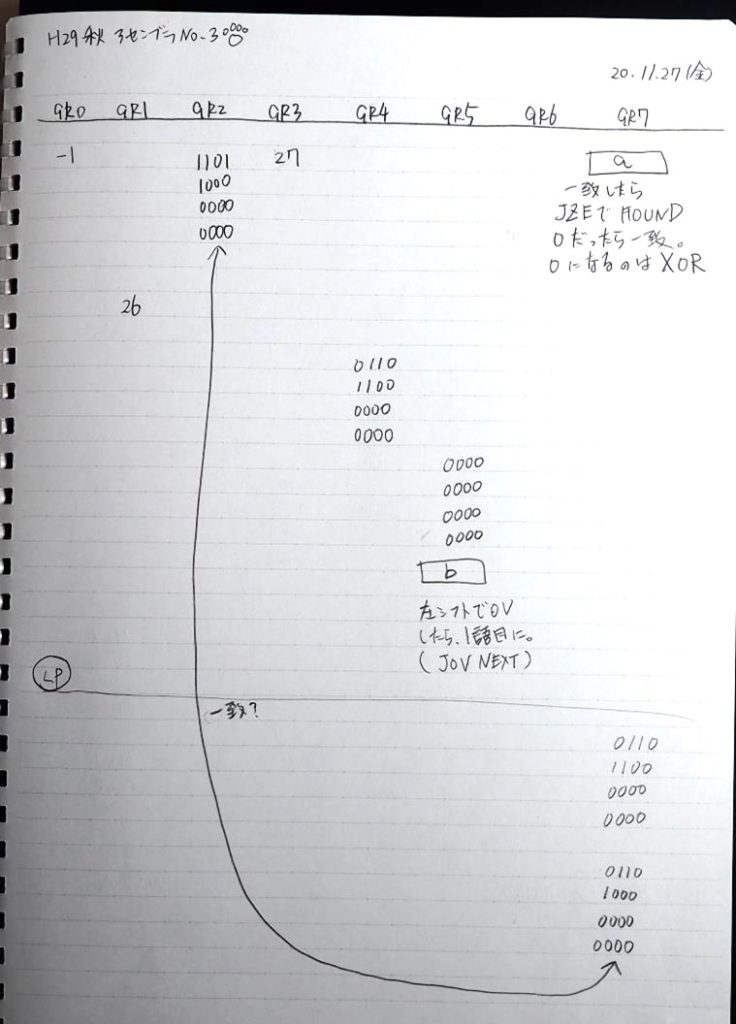
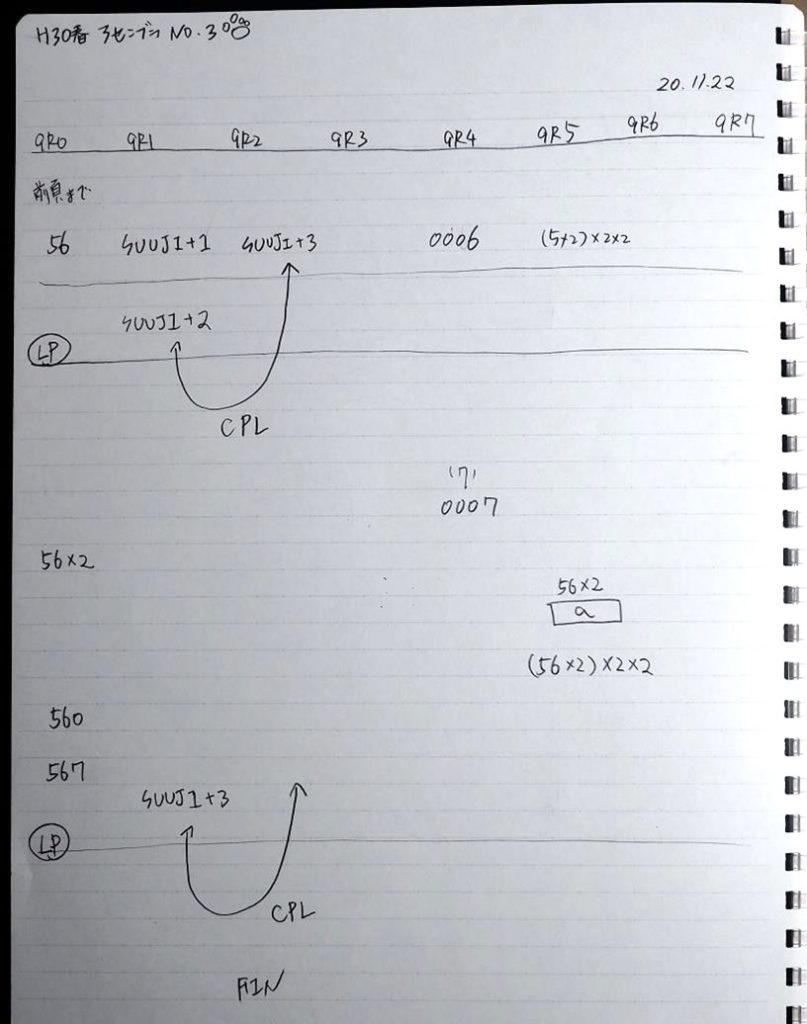
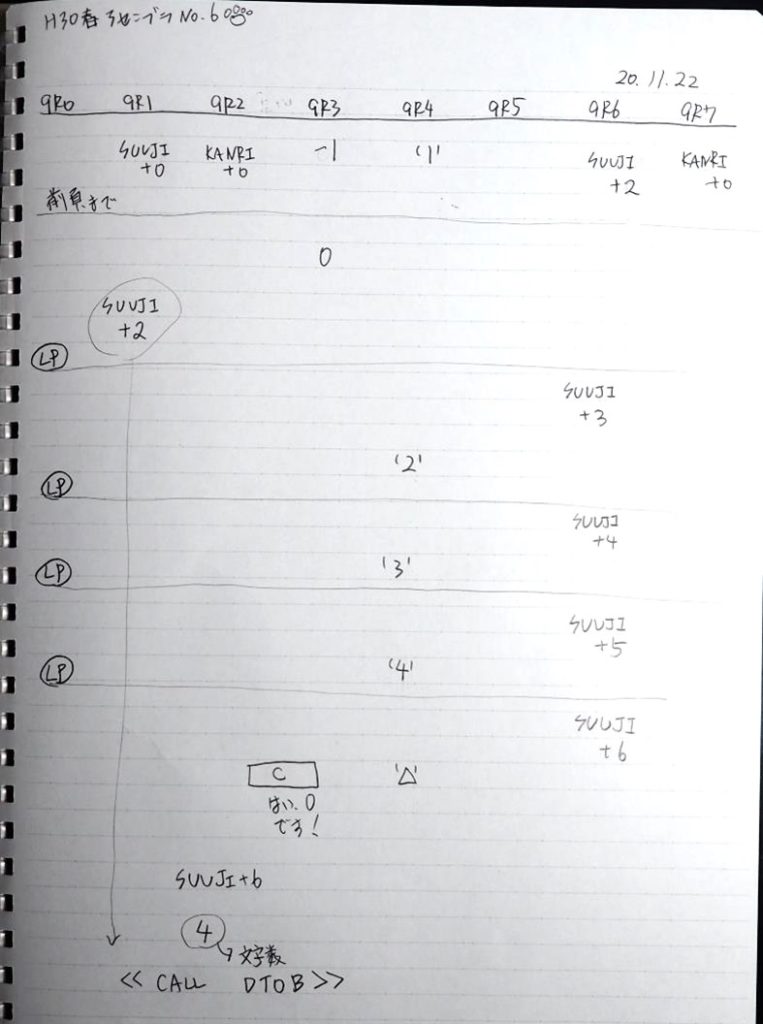
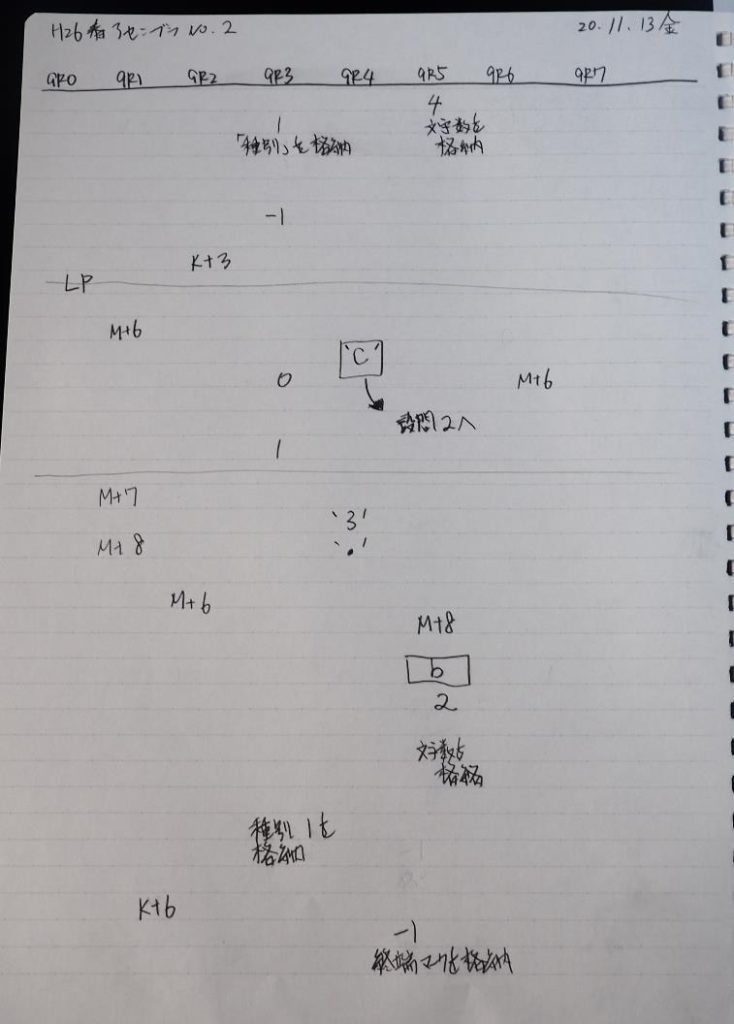
ノートです。
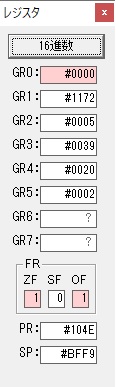
終了しました。
コーン茶です。個人的にはとても美味しいと思いますが、どうなんでしょうね。
では、プログラム2へ行きます。
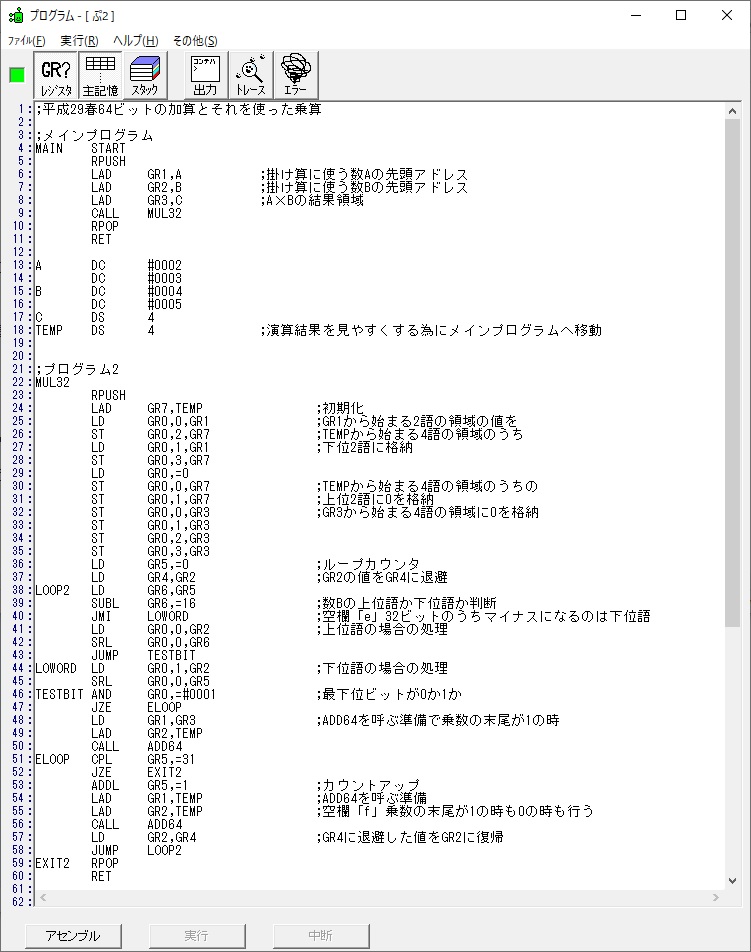
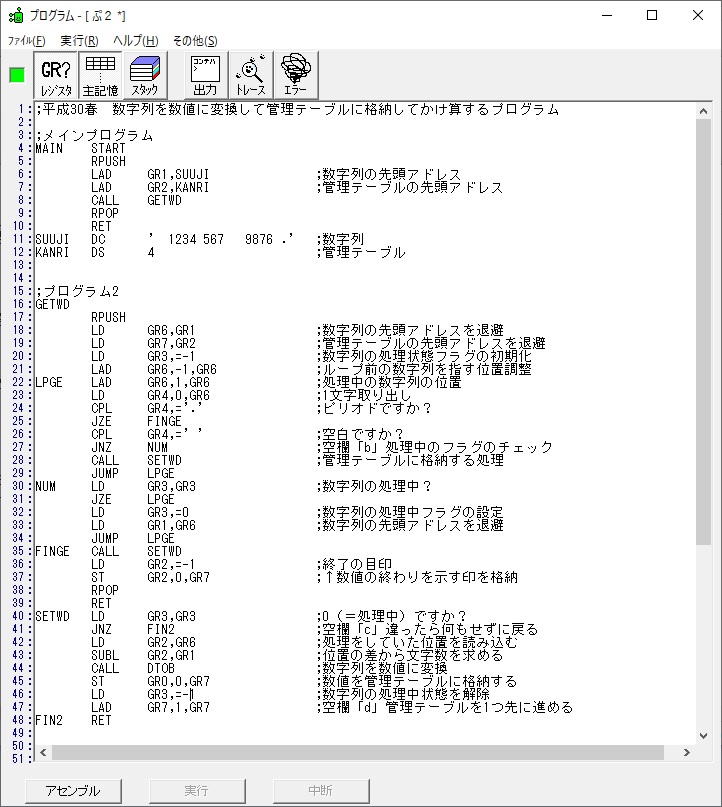
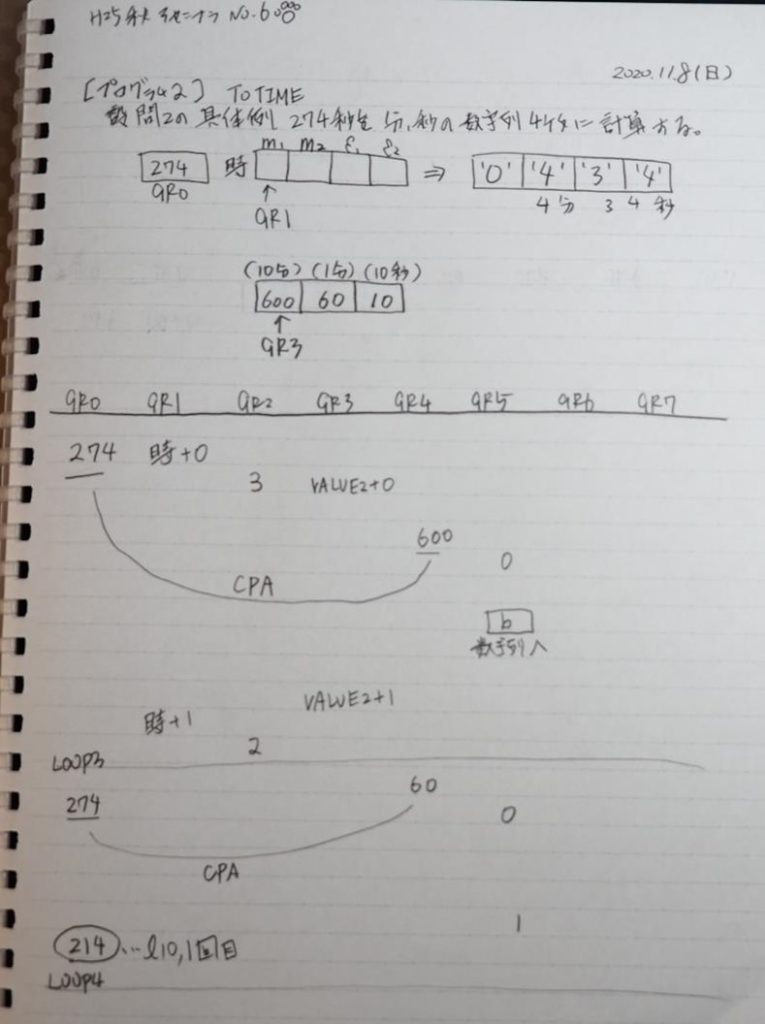
[プログラム2] TOTIME
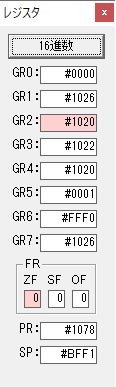
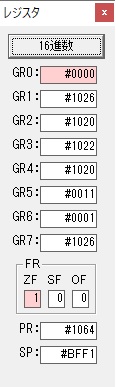
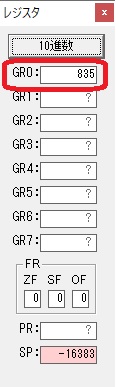
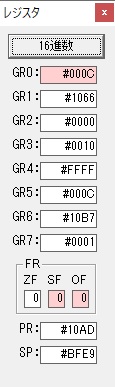
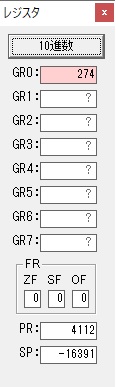
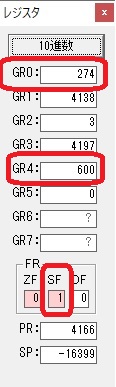
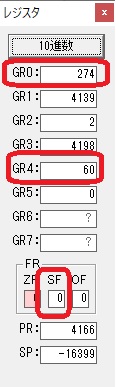
GR0に274秒が入りました。
GR1にJIKAN(時間)の先頭アドレスが入り、プログラム2のTOTIMEが呼び出されました。ループカウンタ3が入りました。
割る数の先頭アドレスが入り、10分の600秒が入りました。
計算に使うGR5が初期化されました。
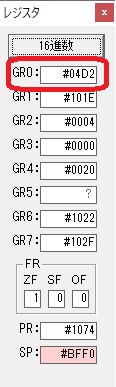
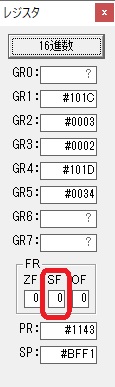
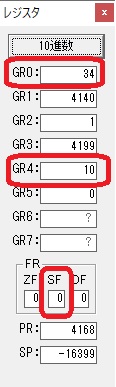
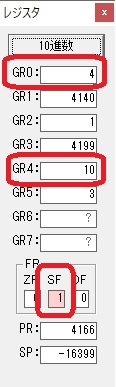
274秒と600秒が比較され、サインフラグが1、つまり10分の桁分が無かったと判断されます。
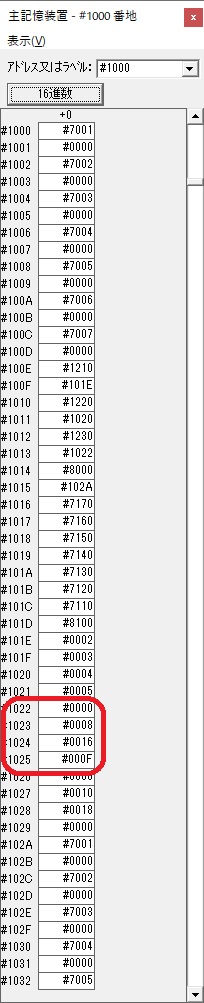
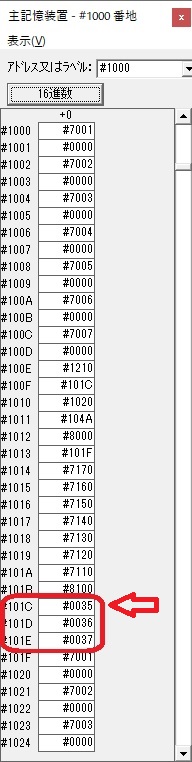
0が数字列「0」になりました。48と入っていますが、これは16進数で0030です。
「0」が格納されました。
GR3の割る数VALUE2が1つ先に進み、GR1の格納領域JIKANも1つ進み、ループ回数が1つ減りました。
ループ3へ
割る数に60が入りました。
演算結果が初期化されました。
1分60秒と比較して、274秒の方が多いので、サインフラグが0です。
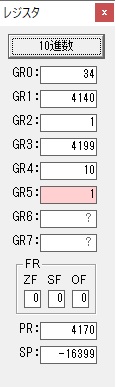
1分の分がカウントされました。
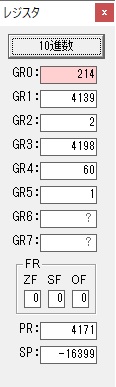
GR0の274からGR4の60が減算され、GR0が214になりました。・・・10行目の1回目
ループ4へ
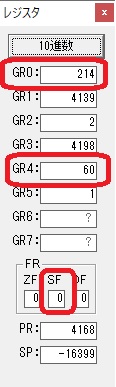
1分60秒と比較して、214秒の方が多いので、サインフラグが0です。
2分の分がカウントされました。
GR0の214からGR4の60が減算され、GR0が154になりました。・・・10行目の2回目
ループ4へ
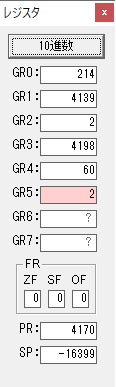
1分60秒と比較して、154秒の方が多いので、サインフラグが0です。
3分の分がカウントされました。
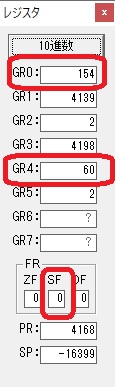
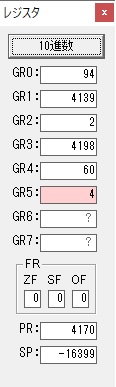
GR0の154からGR4の60が減算され、GR0が94になりました。・・・10行目の3回目
ループ4へ
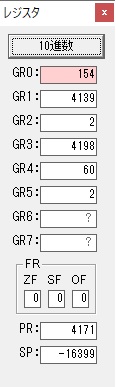
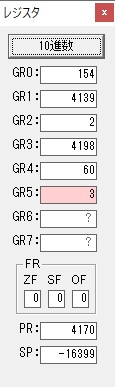
4分の分がカウントされました。
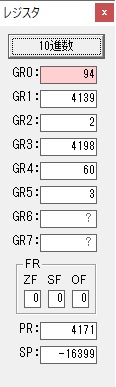
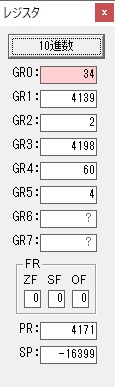
GR0の94からGR4の60が減算され、GR0が34になりました。・・・10行目の4回目
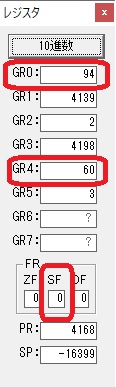
ループ4へ
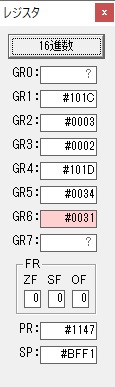
4が数字列「4」になりました。52と入っていますが、これは16進数で0034です。
「4」が格納されました。
GR3の割る数VALUE2が1つ先に進み、GR1の格納領域JIKANも1つ進み、ループ回数が1つ減りました。
ループ3へ
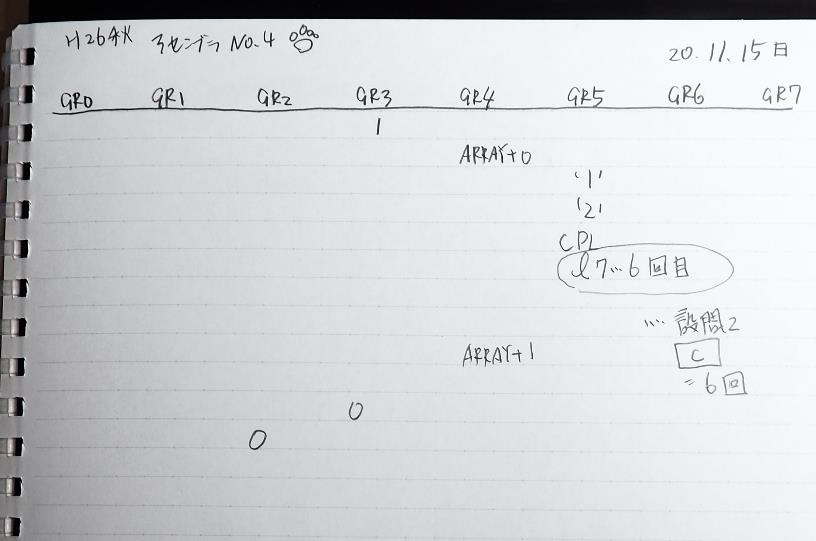
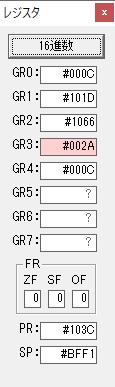
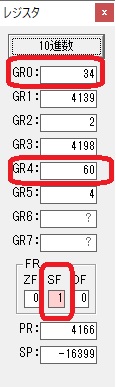
割る数の10が入りました。残りの秒数34を10×3で「3」、余りの分の「4」にする為に、この割る数10を使います。
計算用レジスタのGR5が初期化されました。
10秒と比較して、34秒の方が多いので、サインフラグが0になりました。
10秒1つ分がカウントされました。
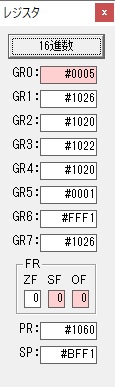
GR0の34からGR4の10が減算され、GR0が24になりました。・・・10行目の5回目
ループ4へ
10秒2つ分がカウントされました。
GR0の24からGR4の10が減算され、GR0が14になりました。・・・10行目の6回目
ループ4へ
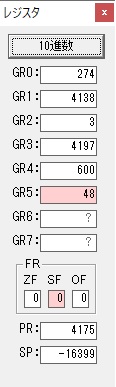
10秒3つ分がカウントされました。
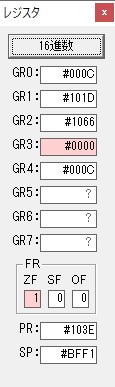
GR0の14からGR4の10が減算され、GR0が4になりました。・・・10行目の7回目
これより、設問2のeは7回になります。
ループ4へ
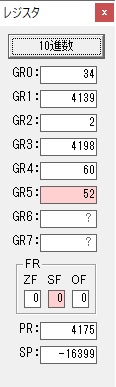
3が数字列「3」になりました。51と入っていますが、これは16進数で0033です。
「3」が格納されました。
GR3の割る数VALUE2が1つ先に進み、GR1の格納領域JIKANも1つ進み、ループ回数が1つ減って0になりました。なので、分岐せず下に行きます。
GR0の4が数字列「4」になりました。52と入っていますが、これは16進数で0034です。16×3=48、それに4を足して52です。
「4」が格納されました。
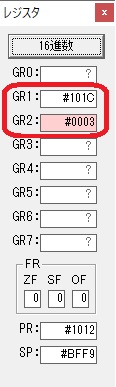
メインプログラムに戻ります。
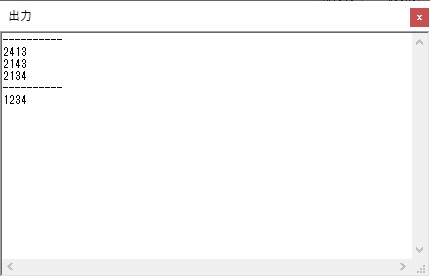
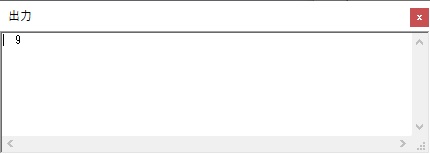
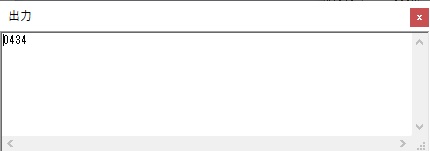
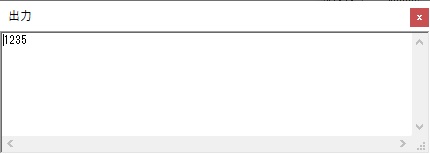
数字列が表示されました。
プログラム2はこちらになります。
;平成25年秋メインプログラム、プログラム2
・・・・で、結局寝て次の日になりました(=^・^=)
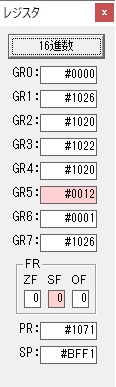
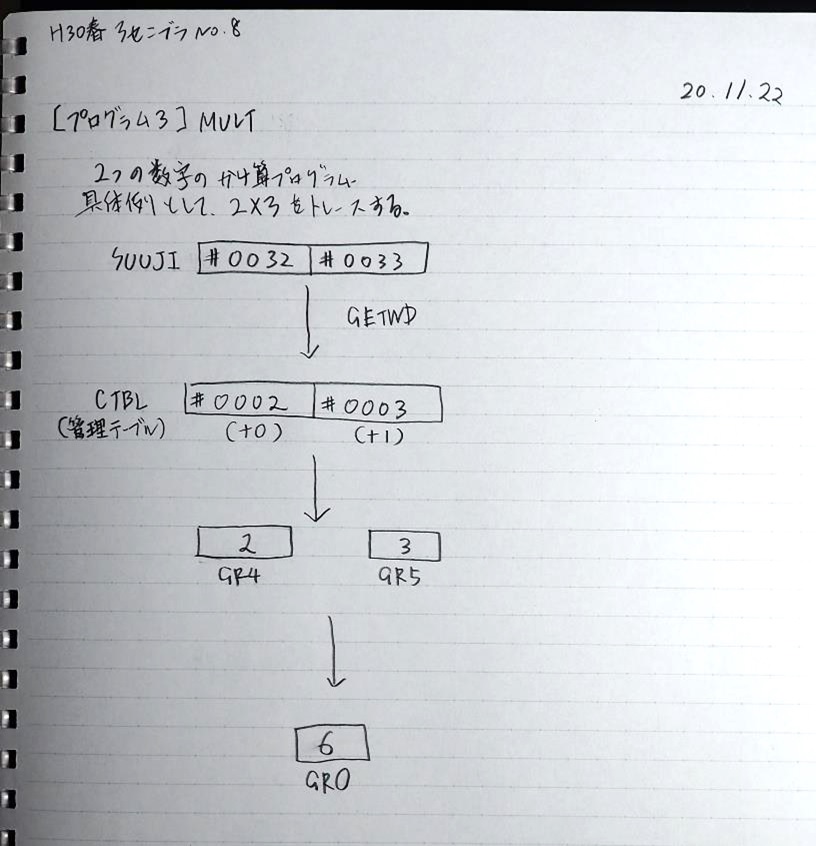
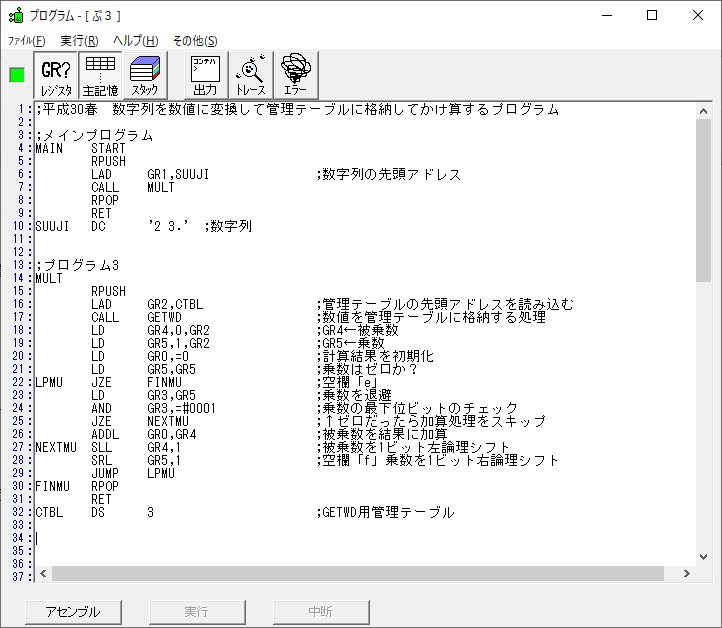
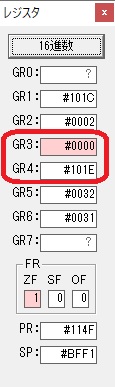
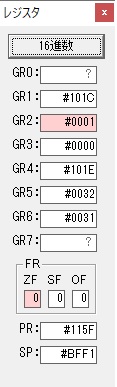
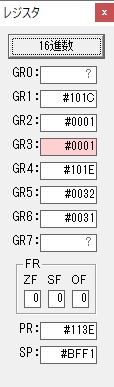
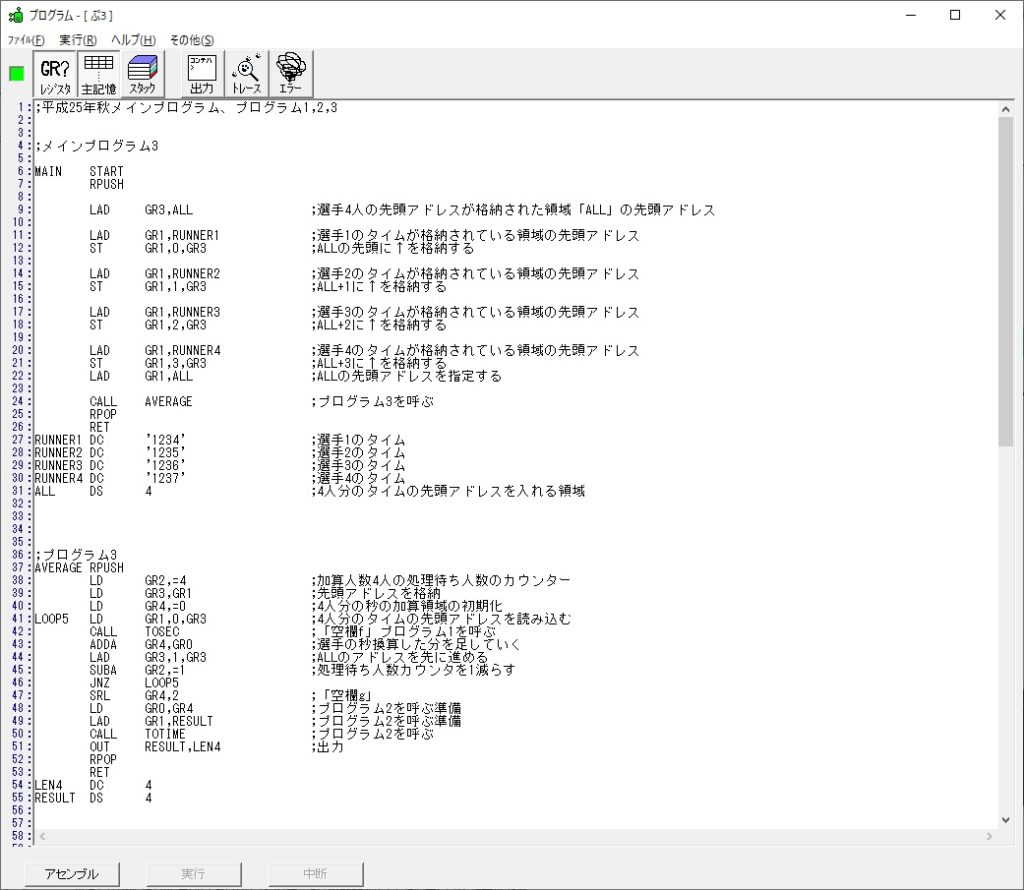
プログラム3のAVERAGEは、選手4人のタイムの平均を求めます。
RUNNER1 ‘1234’…(RUNNER1+0に数字列の「1」、RUNNER1+1に数字列の「2」、RUNNER1+2に数字列の「3」、RUNNER1+3に数字列の「4」)
これらの先頭アドレスを領域ALLに格納します。
ALL+0 RUNNER1+0
RUNNER1のアドレスはGR1、ALLのアドレスはGR3を使用します。
これでプログラム3の(AVERAGE)を呼びます。
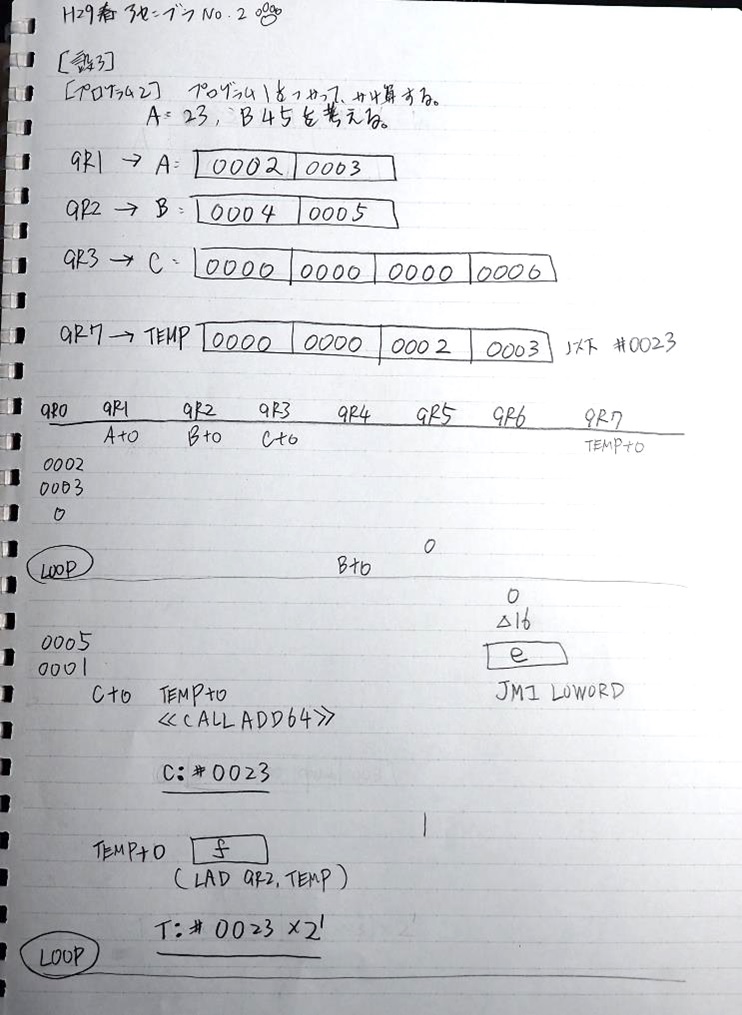
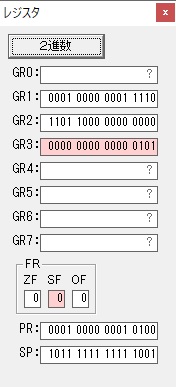
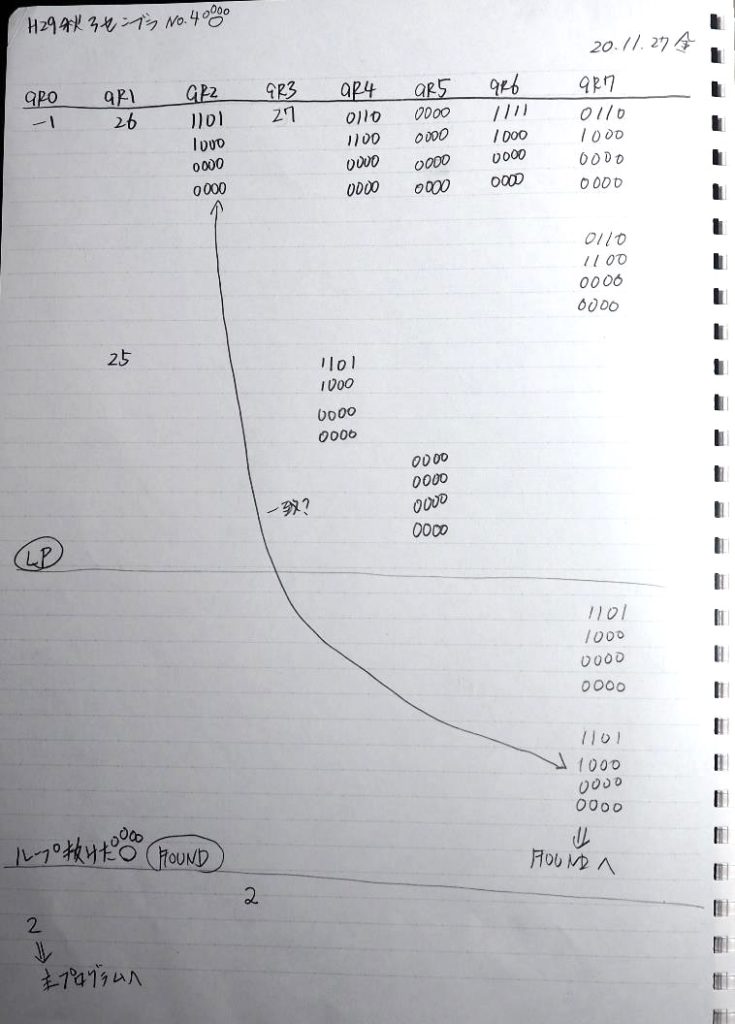
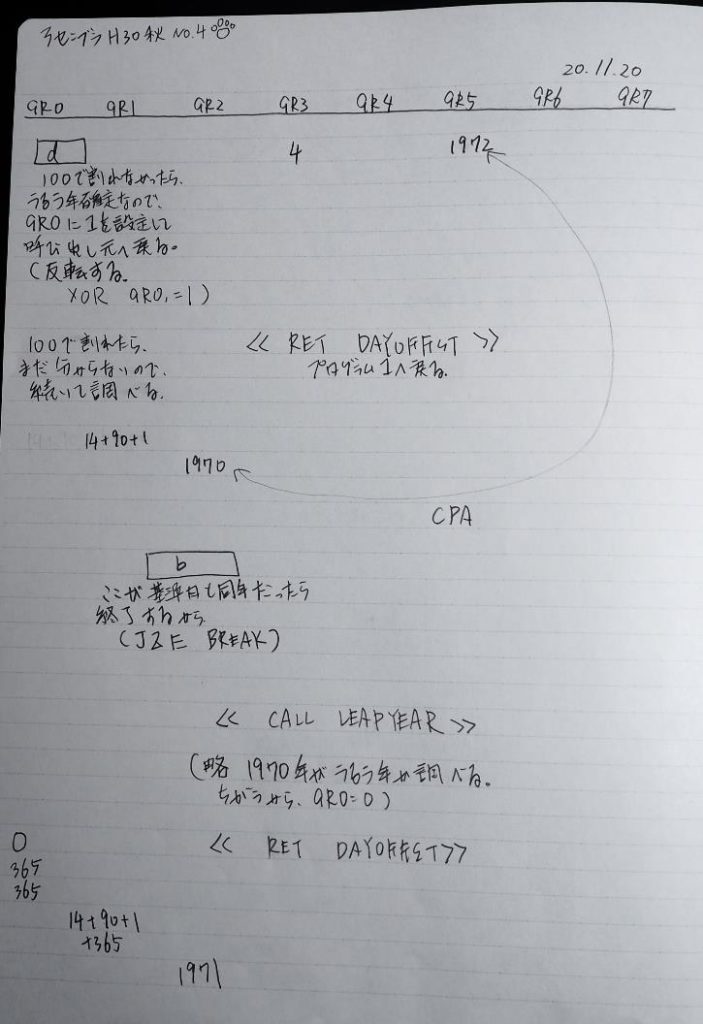
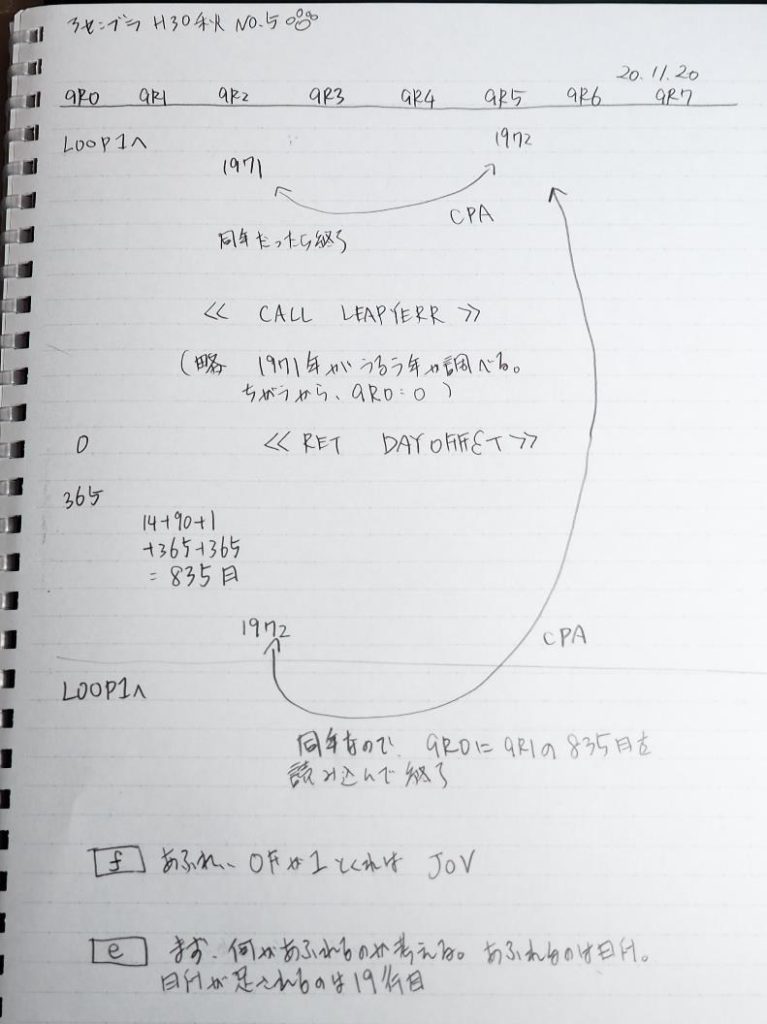
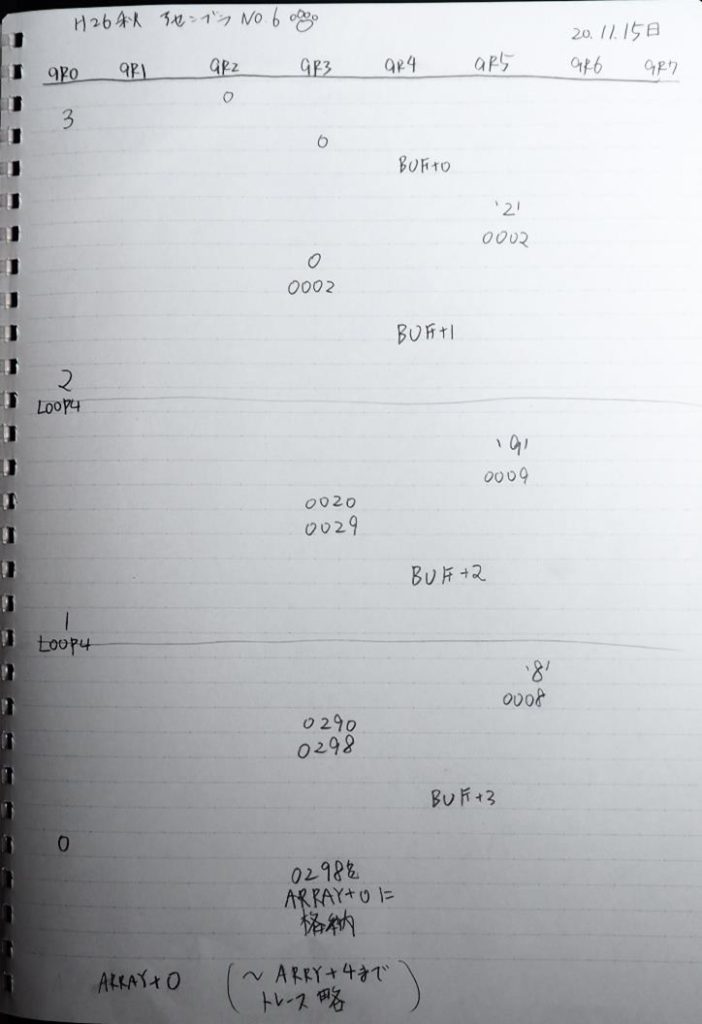
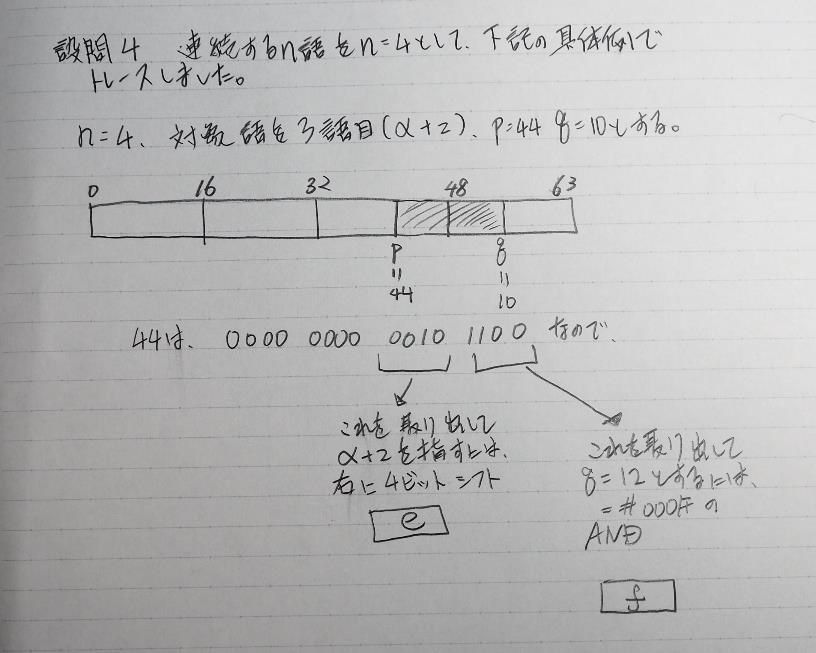
ここまでの説明をノートにまとめました。
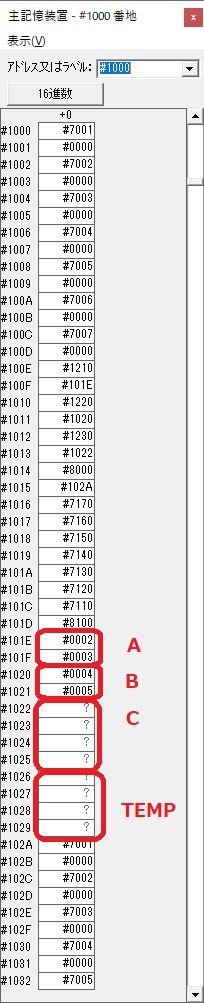
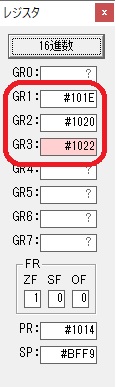
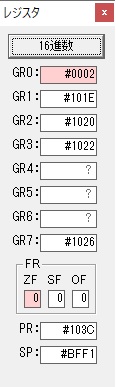
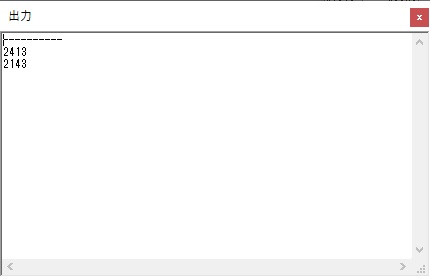
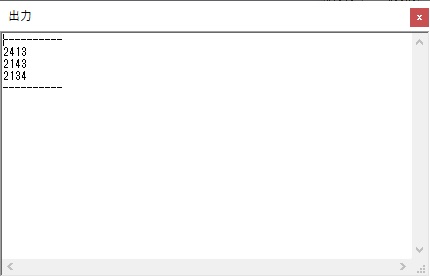
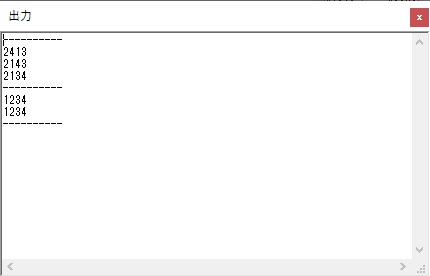
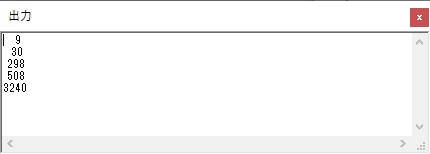
今回は、シミュレーターの一括実行(このシミュレーターの場合は「実行メニューから」)で行い、出力結果はこのようになりました。
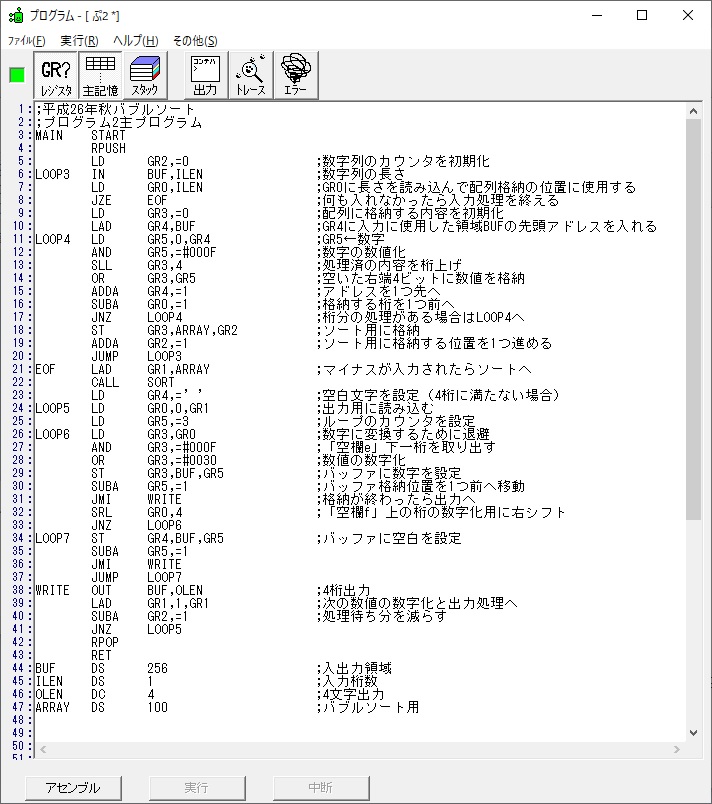
以下がプログラムになります。
プログラム1,2は変わらないので、画像は省略します。
;平成25年秋メインプログラム、プログラム1,2,3
トレースノートはこちらです。
今度受けるので、自分の勉強になりました。
長々とまとまらなかったり、色々と下らないことも書いて失礼もあったかもしれませんが、ここまでお付き合い頂き本当にありがとうございました。
シミュレーターと過去問を解くまでの勉強に使った参考書はこちら
アセンブラ過去問プログラミング アセンブラ自作サンプルへ 基本情報技術者試験トップへ 息抜きに、写真で癒し(=^・^=)